- 이번 포스팅으론 원격 환경에 위치한 웹캠 영상을 Python 서버로 받아와 영상 프레임을 처리하는 방식을 알아보겠습니다.
본 기술을 익힘으로써 기대되는 응용 능력으로는,
원격 모니터링 및 보안 서비스, 영상 채팅 서비스에서의 인공지능 필터링, IoT 에서의 디바이스 원격 조작 등에 사용되는 기술 원리를 이해하고 구현할 수 있는 가장 기본적인 능력을 갖출 수 있을 것입니다.
- 본 게시글에서 실습할 최종 산출물은,
ReactJS 에서 웹캠으로 받아온 영상을 네트워크 통신으로 Python 서버에 전송하여,
해당 서버에서 간단한 영상 분석 및 합성을 하는 소프트웨어를 만들 것입니다.
웹캠 디바이스 - 클라이언트 브라우저 -- [영상 데이터 네트워크 통신] -- Python 서버 - 영상 합성 - 영상 표시
(WebRTC)
- 본 게시글에서 영상 데이터를 원격으로 전송하고 받기 위한 기술은 WebRTC 를 사용할 것입니다.
- WebRTC(Web Real-Time Communication)란,
웹 애플리케이션이나 모바일 애플리케이션에서 실시간 음성, 비디오, 데이터 통신을 구현할 수 있도록 돕는 기술입니다.
실시간으로 미디어와 데이터를 교환할 수 있게 해주며, 다양한 애플리케이션에서 화상 회의, P2P 음성 통화, 실시간 게임, 파일 전송 등을 구현하는 데 사용되는 기술로,
클라이언트를 통하지 않는 P2P 통신을 지원하며, 지연이 적고 성능이 좋은 기술입니다.
- WebRTC의 주요 특징
1. 다양한 환경 지원:
대부분의 주요 웹 브라우저(Chrome, Firefox, Safari, Edge 등) 및 IoT 디바이스, 앱, 서버 프레임워크에서도 사용할 수 있는 기술입니다. (IoT 디바이스의 경우 Rasberry Pi 등의 고성능 장치에서 이를 지원해야 사용 가능)
2. 보안:
WebRTC는 DTLS(Datagram Transport Layer Security) 및 SRTP(Secure Real-time Transport Protocol)를 사용하여 모든 미디어 스트림(오디오, 비디오)을 암호화합니다. 이로 인해 보안성이 높습니다.
3. 응답성(지연 시간):
WebRTC는 지연 시간이 매우 낮습니다. 이는 실시간 통신이 요구되는 애플리케이션(예: 영상 회의, 실시간 게임 등)에서 중요한 특징입니다.
4. P2P(피어 투 피어) 통신:
WebRTC는 노드 간 직접적인 P2P 연결을 허용하여, 따로 서버를 거치지 않고 데이터를 주고받을 수 있습니다.
이 방식은 서버 부하를 줄이고, 지연 시간(latency)을 최소화하는 데 유리하며,
P2P 연결 구현시 서버의 역할은 각 노드의 접근 주소 데이터 정도를 다루면 됩니다.
5. 다양한 통신 유형:
WebRTC는 오디오, 비디오, 데이터의 세 가지 주요 통신 방식으로 사용할 수 있습니다. 이를 통해 다양한 형태의 실시간 통신을 구현할 수 있습니다.
- 위와 같은 특징에서 실시간성이 요구되는 서비스를 가정하여 WebRTC 를 선정하였습니다.
RTSP, RTMP 와 같은 다른 기술 역시 고려할 수 있습니다.
(WebRTC 영상 통신 구현)
- 가장 먼저, 클라이언트에서 보낸 영상 데이터를 서버에서 받는 부분을 구현하겠습니다.
물리적으로 떨어진 상태를 가정한 두 노드에서 영상 데이터를 공유하는 방식을 이해하고 구현하고 테스트 하는 것이 목적입니다.
- Python 서버
먼저 영상을 받아들이는 서버를 구현하겠습니다.
본 게시글에서는 사용하는 주요 기술은,
1. FastAPI : Python 웹 서버 프레임워크입니다. Python 코드를 서버 프로그램으로 동작하도록 해줍니다.
2. aiortc : WebRTC 및 RTC 관련 기능을 처리하는 라이브러리입니다.
여기서는 WebRTC 연결을 통해 클라이언트와 서버 간의 비디오 스트리밍을 처리합니다.
3. OpenCV : 클라이언트 측에서 받아온 영상 데이터를 잘 받아오고 있는지 확인하기 위해 사용합니다.
위와 같습니다.
코드를 소개하자면 아래와 같습니다.
import cv2
import asyncio
import av
from fastapi import FastAPI, Request
from aiortc import RTCPeerConnection, RTCSessionDescription
from fastapi.middleware.cors import CORSMiddleware
# FastAPI 객체 생성 및 CORS 설정(all open)
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# WebRTC 연결 주소 매핑 (외부에서 http://localhost:8000/offer 이렇게 접속)
# 클라이언트(WebRTC Peer)로부터 offer SDP(Session Description Protocol)를 받아 WebRTC 연결을 시작 하는 엔드포인트
# 클라이언트는 /offer 의 request 에 JSON 으로 SDP 정보를 보냄
@app.post("/offer")
async def offer(request: Request):
# 클라이언트에서 받은 offer SDP 를 저장
data = await request.json()
offer_sdp = data["sdp"]
# Peer 연결 생성
pc = RTCPeerConnection()
# 데이터 수신부 콜백
@pc.on("track")
def on_track(track):
# 영상 데이터를 받은 경우에 대한 처리
if track.kind == "video":
# 영상 데이터 프레임 처리 함수
async def display_video():
while True:
# track 에서 영상 프레임 받아 오기
frame: av.VideoFrame = await track.recv()
# 프레임 데이터 이미지 형식 변경
img = frame.to_ndarray(format="bgr24") # OpenCV용으로 변환
# OpenCV 창에 영상 img 표시
cv2.imshow("WebRTC Stream", img)
# OpenCV 창 닫기 조건
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
# 프레임 관련 처리 함수를 비동기로 실행
asyncio.create_task(display_video())
# 클라이언트의 offer SDP 를 수락
await pc.setRemoteDescription(RTCSessionDescription(sdp=offer_sdp["sdp"], type=offer_sdp["type"]))
# 서버에서 answer SDP 를 생성 후 설정
answer = await pc.createAnswer()
await pc.setLocalDescription(answer)
# 클라이언트에 서버의 answer SDP 를 응답으로 전송
# 클라이언트는 이 정보를 통해 WebRTC 연결을 완료
return {"sdp": {"sdp": pc.localDescription.sdp, "type": pc.localDescription.type}}
상세 설명은 각 코드별 주석에 첨부해 두었습니다.
간략히 설명하자면,
FastAPI 로 서버를 실행시키고, 클라이언트와 WebRTC 연결 이후,
on_track 콜백에서 클라이언트에서 보낸 데이터인 track 을 처리하는 코드입니다.
display_video 콜백에서 실제로 영상 데이터의 프레임 이미지를 다루는 코드를 확인할 수 있으며,
이곳을 수정하면 원격 영상을 파이썬 서버에서 처리할 수 있는 것입니다.
예를들어 tensorflow 와 같은 딥러닝 라이브러리를 응용해 이미지를 분석해서 이상 탐지를 하거나,
OpenCV 에서 영상 데이터를 수정하거나,
원격으로 보내온 영상 데이터를 파일로 저장을 하는 등의 기능을 추가할 수 있는 것입니다.
위와 같이 갖춰진 서버 코드의 위치에서,
uvicorn server:app --host 0.0.0.0 --port 8000
위와 같이 명령어를 입력해서 FastAPI 서버를 실행시키면 정상 동작을 확인할 수 있습니다.
- ReactJS(Typescript) 클라이언트
클라이언트는 단순히 웹캠 영상을 전달하는 것 뿐입니다.
고로 웹캠이 필요하며, 코드는 아래와 같습니다.
const View: React.FC = () => {
const localVideo = useRef<HTMLVideoElement>(null);
const pcRef = useRef<RTCPeerConnection | null>(null);
useEffect(() => {
const start = async () => {
// 웹캠 비디오 스트림 요청(권한을 허용하면 MediaStream 객체가 반환됩니다.)
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
// <video> 태그에 스트림을 연결하여 로컬 화면에 영상 표시.
if (localVideo.current) localVideo.current.srcObject = stream;
// 새로운 RTCPeerConnection을 생성하고, ref에 저장하여 나중에도 접근 가능하게 만듭니다.
const pc = new RTCPeerConnection();
pcRef.current = pc;
// WebRTC 연결에 비디오 트랙을 추가합니다.(서버로 비디오 스트림을 전송할 준비 완료.)
stream.getTracks().forEach(track => pc.addTrack(track, stream));
// 클라이언트가 offer를 생성하고, 자신에게 설정합니다.
const offer = await pc.createOffer();
await pc.setLocalDescription(offer);
// FastAPI 서버의 /offer 엔드포인트에 offer SDP를 전송합니다.
const response = await fetch('http://localhost:8000/offer', {
method: 'POST',
body: JSON.stringify({ sdp: pc.localDescription }),
headers: { 'Content-Type': 'application/json' }
});
// 서버로부터 받은 answer SDP를 사용해 PeerConnection을 완성합니다.
// 이제 클라이언트는 서버와 WebRTC를 통해 영상 스트림을 전송합니다.
const answer = await response.json();
await pc.setRemoteDescription(new RTCSessionDescription(answer.sdp));
};
start();
}, []);
return <video ref={localVideo} autoPlay playsInline />;
};
위 코드 역시 주석을 상세히 달아두었으므로 참고하시면 되며,
단순히 웹캠 디바이스에서 영상을 받아와 화면에 표시하고, 비디오 스트림을 동시에 WebRTC 로 전송하는 코드입니다.
본 게시글에서는 더이상 수정할 코드는 없지만, 추후 비정상적인 연결 종료, 인터넷 연결 끊김, 그외 UI 처리 등을 고려해야 할 것입니다.
- 위와 같이 준비된 코드를 가지고 실행해보겠습니다.
웹캠 디바이스 - 클라이언트 브라우저 -- [영상 통신] -- Python 서버 - 영상 표시
위와 같은 구조로 실행되며,
파이썬 서버를 먼저 실행하고, ReactJS 를 실행시켜 브라우저에서 웹캠 접근 권한을 승인하기만 한다면,
실제 WebRTC 를 사용하여 영상이 공유됨을 확인할 수 있습니다.
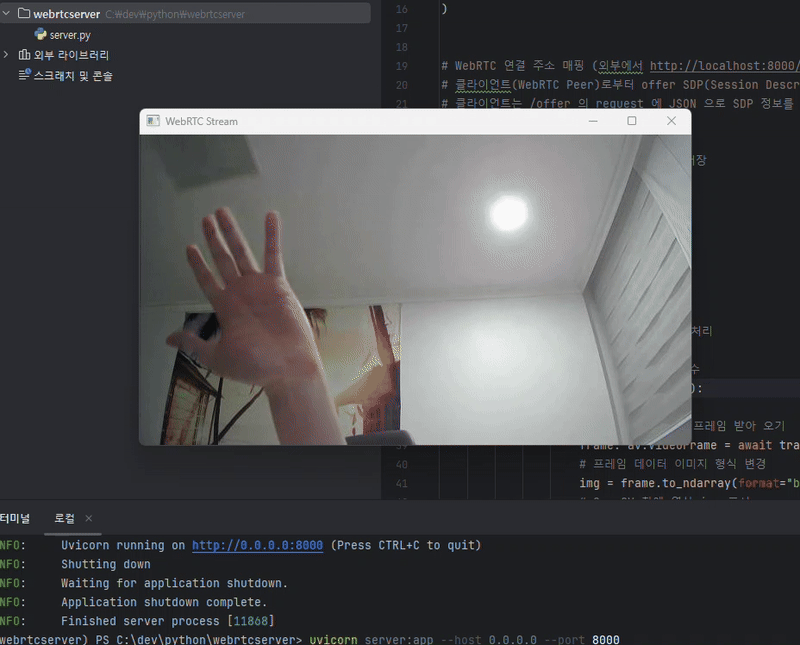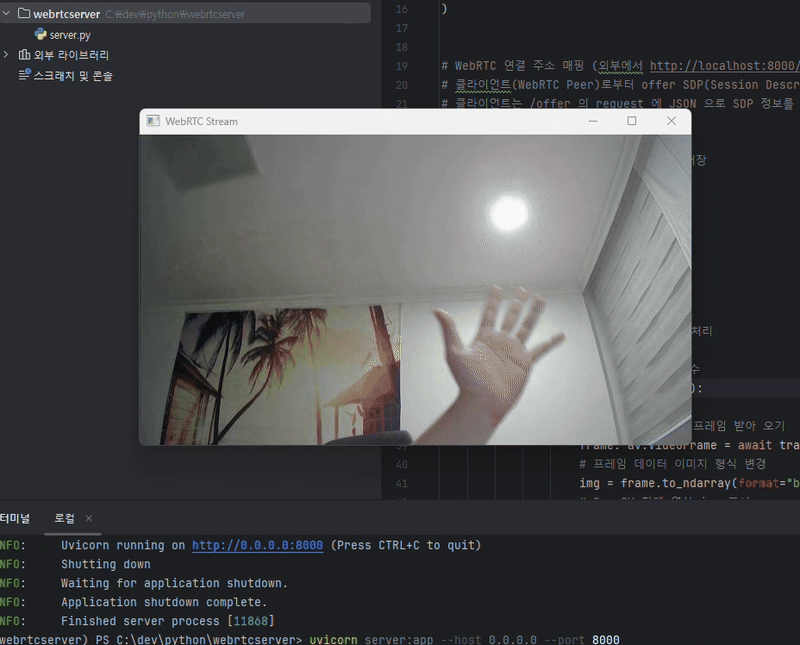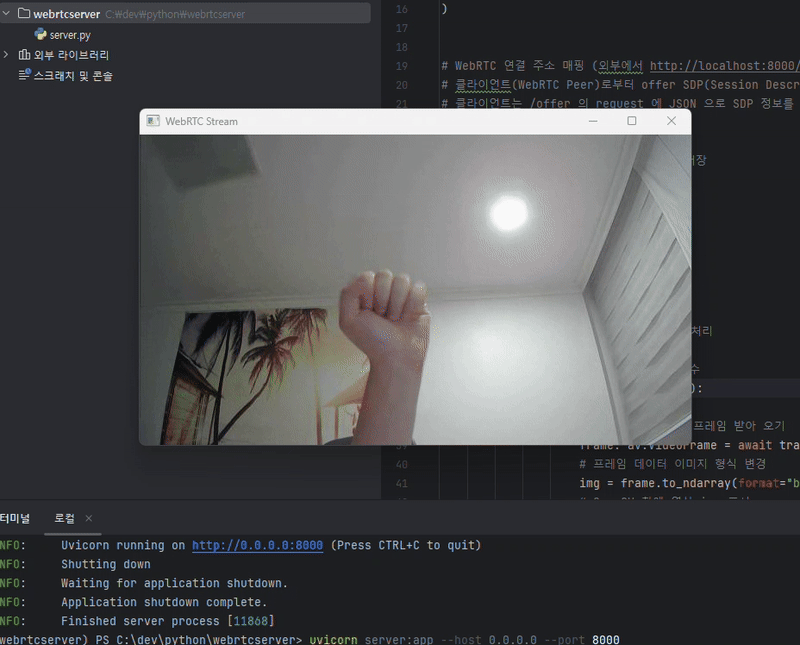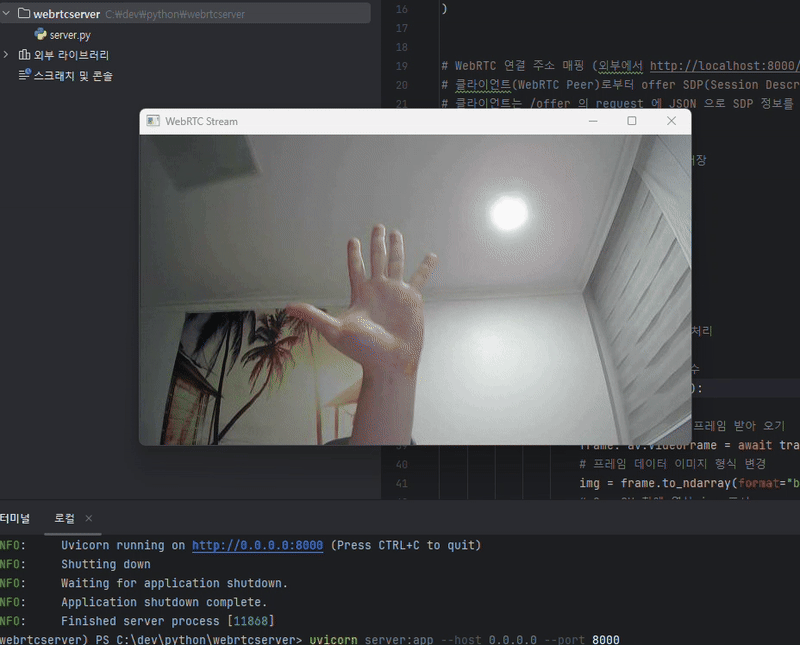
위와 같이 ReactJS 클라이언트에서 영상 데이터를 보내오면 Python 서버에서 OpenCV 를 통해 영상 프레임을 화면창에 띄워 보여주는 것을 볼 수 있습니다.
이로서 물리적 거리에 상관 없이 원격으로 영상 데이터를 공유할 수 있게 되었습니다.
(Python 영상 처리 추가)
- 다른 서버, 혹은 클라이언트로도 영상 통신이 가능하지만, 굳이 Python 서버에서 영상을 받도록 예시를 구현한 이유는,
파이썬 언어가 인공지능, 컴퓨터 비전 등의 여러 유용한 기능들을 쉽게 사용할 수 있도록 지원해주기 때문입니다.
위 실습으로 Python 서버에서 영상 프레임을 가져와 다룰 수 있는 것을 확인하였으므로,
이에 더해서 간단히 영상 처리를 하는 방식으로 응용한 후 게시글을 마치도록 하겠습니다.
filter.py 라는 파일로 아래와 같이 영상 합성 코드를 입력합니다.
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier(
cv2.data.haarcascades + 'haarcascade_frontalface_default.xml'
)
overlay_img = cv2.imread('overlay.png', cv2.IMREAD_UNCHANGED) # PNG with alpha
def overlay_image(background, overlay, x, y, w, h):
overlay_resized = cv2.resize(overlay, (w, h))
if overlay_resized.shape[2] == 4:
overlay_rgb = overlay_resized[:, :, :3]
mask = overlay_resized[:, :, 3] / 255.0
else:
overlay_rgb = overlay_resized
mask = np.ones((h, w))
roi = background[y:y+h, x:x+w]
for c in range(3):
roi[:, :, c] = roi[:, :, c] * (1 - mask) + overlay_rgb[:, :, c] * mask
background[y:y+h, x:x+w] = roi
return background
def process_frame(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(
gray, scaleFactor=1.1, minNeighbors=5, minSize=(100, 100)
)
for (x, y, w, h) in faces:
# 얼굴 영역을 살짝 키워서 일렁임 완화 + 잘 덮이게
scale = 1.5 # 1.2 ~ 2.0 조절 가능
new_w = int(w * scale)
new_h = int(h * scale)
new_x = x - (new_w - w) // 2
new_y = y - (new_h - h) // 2
# 이미지 경계 벗어나지 않도록 클리핑
new_x = max(0, new_x)
new_y = max(0, new_y)
if new_x + new_w > frame.shape[1]: new_w = frame.shape[1] - new_x
if new_y + new_h > frame.shape[0]: new_h = frame.shape[0] - new_y
frame = overlay_image(frame, overlay_img, new_x, new_y, new_w, new_h)
return frame
코드 설명은,
이미지 파일을 opencv 에서 분석하여,
사람의 얼굴 부분에 가면 이미지를 씌워주는 기능입니다.
얼굴 인식 및 영역 파악 -> 얼굴 영역의 좌표를 기반으로 이미지 파일을 덮어씌우기
위와 같은 간단한 기능입니다.
컴퓨터 비전을 잘 아시는 분이시라면 아실텐데,
위 방식은 일단 성능이 그다지 좋은 방식은 아닙니다.(보다 좋은 객체 탐지 모델을 사용해서 GPU 가속 등을 사용해 성능 향상 가능)
실습을 위해선 이 파일을 받아서 filter.py 파일 위치로 넣어주고,
얼굴에 합성할 이미지 파일도 준비해주면 됩니다.
이제 앞서 작성한 서버 코드의 on_track 콜백에,
@pc.on("track")
def on_track(track):
# 영상 데이터를 받은 경우에 대한 처리
if track.kind == "video":
# 영상 데이터 프레임 처리 함수
async def display_video():
while True:
# track 에서 영상 프레임 받아 오기
frame: av.VideoFrame = await track.recv()
# 프레임 데이터 이미지 형식 변경
img = frame.to_ndarray(format="bgr24") # OpenCV용으로 변환
img = filter.process_frame(img) # 얼굴 이미지 덮기 처리
# OpenCV 창에 영상 img 표시
cv2.imshow("WebRTC Stream", img)
# OpenCV 창 닫기 조건
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
# 프레임 관련 처리 함수를 비동기로 실행
asyncio.create_task(display_video())
위와 같이 img 를 처리하는 부분에 filter.process_frame 함수만 추가시켜 주시면 끝입니다.
결과는 아래와 같습니다.
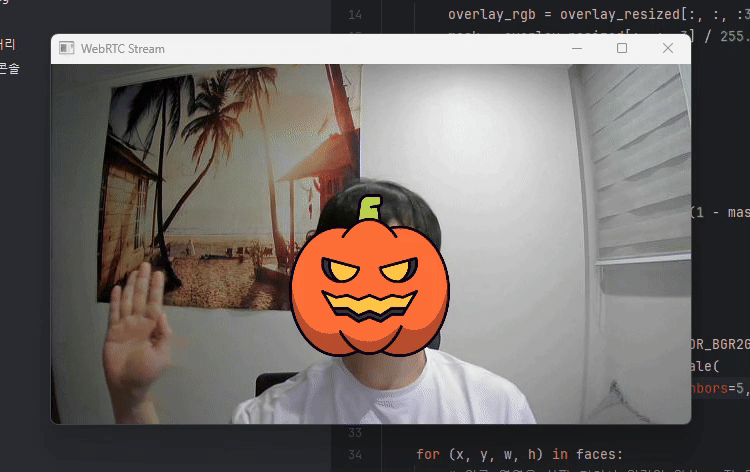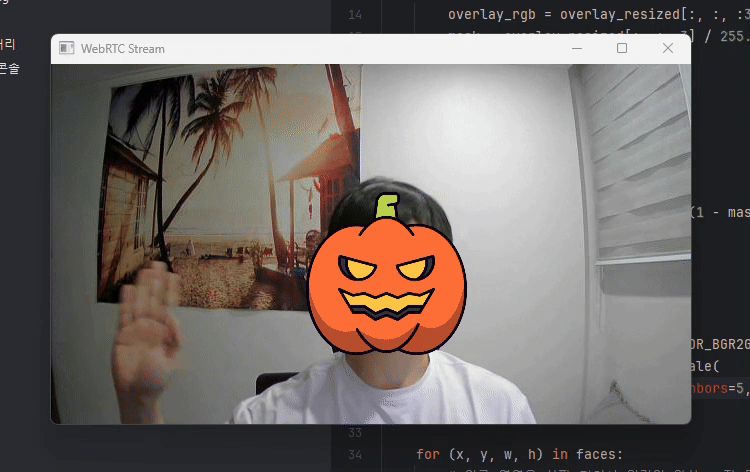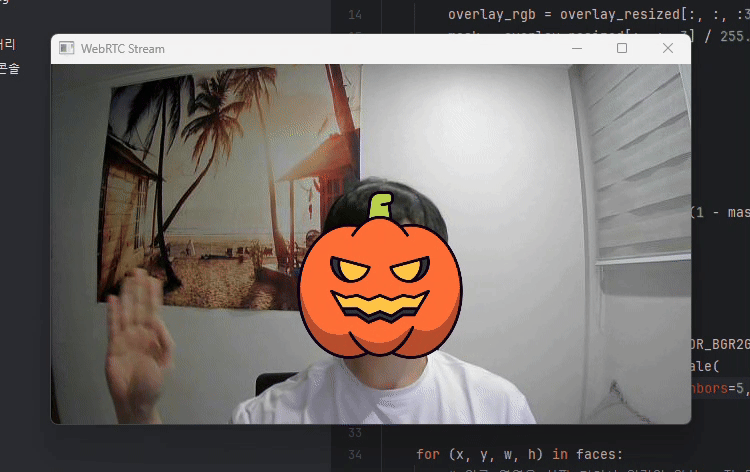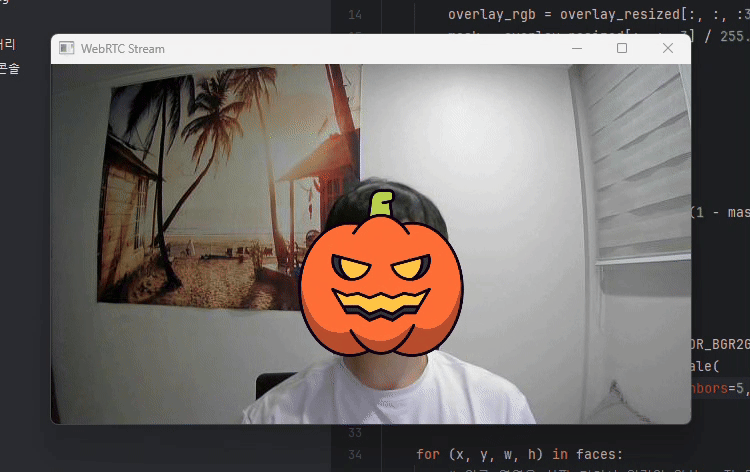
이상입니다.
위와 같은 결과물을 기반으로 하여,
표정 탐지, 재스쳐 탐지 등의 기능을 사용하여 보다 동적인 애니메이션을 적용하거나,
컴퓨터 비전, 딥러닝 등의 기술, WebRTC 서버 관련 보다 치밀한 처리로 개선해나가면 재밌는 서비스를 만들 수 있을 것입니다.
- 아이디어 정리
WebRTC 는 굉장히 좋은 기술입니다.
특히 P2P 로 연결된다는 점이 좋은 것 같은데,
추후 영상 통신 관련 어느 기업에서나 쉽고 편하게 구현할 수 있는 플러그인을 만들거나,
혹은 중앙에서 트래픽 관리 및 주소 매칭을 해주고, 클라이언트간 통신을 분산하게 하는 솔루션을 직접 구현해 볼 수 있을 것 같습니다.
- Github Repository : https://github.com/RaillyLinker/Python_SimpleWebRtcServer
'Programming > ETC' 카테고리의 다른 글
| IoT MQTT(Message Queuing Telemetry Transport) 프로토콜 설명 및 실시간 통신 실습(Server Docker EMQX 클러스터링, Client Javascript & C++) (0) | 2025.04.15 |
|---|---|
| IoT(Internet of Things, 사물 인터넷) 설명 및 기술 로드맵 (0) | 2025.04.14 |
| [Java] TLV(Tag-Length-Value) 설명 및 해석 함수 구현 (0) | 2024.10.26 |
| [Java] JVM Garbage Collector 정리 (2) | 2024.10.13 |
| [Java] 자바 Thread Dump 개인정리 (0) | 2024.10.13 |