
- 이번 포스팅에선, 이전에 정리했던 "로컬 생성형 AI 답변 시스템 구현" 게시글을 기반으로,
LLM 질의응답 모델을 네트워크 서버로 서빙하는 방법을 알아보겠습니다.
- 먼저 Python 프로젝트를 준비합니다.
저는 IDE 로 Pycharm 을 사용하였습니다.
위에서 소개드린 로컬 생성형 AI 답변 시스템의 프로젝트를 기반으로 시작합니다.

- 이번에 구현할 LLM 질의응답 서비스는 VectorDB 를 적용한 개선 버전을 사용할 것이기에,
이에 대한 내용은,
"VectorDB 를 적용한 RAG 개선" 게시글을 참고하세요.
(서버 프레임워크 FastAPI 적용)
서버 프레임워크는 FastAPI 를 사용할 것이며,
개발 방식은 이전에 정리한 개발 템플릿을 활용할 것입니다.
1. 템플릿에서 모듈단위로 쉽게 초안을 가져올 수 있습니다.
위와 같이 sample_api 모듈을 그대로 복사하여 붙여넣으신 다음,
실행 환경 설정을 위와 같이 설정합니다.
주의할 점은, 작업 디렉터리를 위와 같이 비워두셔야 템플릿 내의 작업 위치에 따른 파일 접근 등의 자동 로직이 정상 동작합니다.
실행 결과는 아래와 같습니다.
이처럼, 모듈단위로 프로젝트를 작성한다면 작성할 기능과 유사한 프로젝트를 만들 때, 빠르게 복사하고 쉽게 수정하는 방식으로 개발이 가능하므로 효율이 올라간다는 것을 알 수 있습니다.
2. 모듈 설계 및 모듈명 변경
전체 서비스를 개발할 때, 모듈을 어떻게 분리할지에 따라 해당 프로젝트의 확장성과 유지보수성이 높아집니다.
이왕 모듈을 분리하기로 했으므로 전체 서비스를 어떤 모듈로 만들지에 대해 설계해봅시다.
현재 만들려는 기능은 쉽게 말해 ChatGPT 질의응답 서버라고 생각하시면 됩니다.
간혹 기능단위까지 모듈을 쪼개서, LLM 모듈, DB 모듈, VectorDB 모듈, 유틸리티 모듈...
이런식으로 구성하시는 분도 있는데, 저의 경우는 기능은 서비스에 종속되며, 모듈의 최소 단위는 서비스의 최소단위라고 생각하고 있습니다.
그 이유는 위에서 보시듯, 모듈 이식의 편의성이 다릅니다.
기능별로 나뉘어져 있다면, 위와 같은 모듈을 하나 이식하는데만 해도 어느 모듈에 어느 모듈이 연결되어 있는지를 다 파악해야하고, 이렇게 되면 결국 코드상 의존성이 모듈간 의존성으로 바뀔 뿐이지, 모듈화의 장점이 사라진다고 생각하기 때문입니다.
결국, 개인 노하우를 말씀드리자면,
모듈을 나눌 때에는 MSA 를 기준으로 마이크로 서비스 단위로 나누는 것이 좋으며,
기술은 모듈 내에서 폴더 구조 등으로 구분하는 것이 모듈 상호간 의존성을 줄일 수 있으며 이해하기 쉽습니다.
판단은 개인에게 맡기며, 저의 경우에는 현 시점의 모듈을 설계할 때,
ChatGPT 질의응답기를 하나의 모듈로 두고 이것 하나만 있어도 충분하다고 봅니다.
추후 인증인가 모듈, 결제 모듈 등을 붙이는 방식으로 확장을 고려하고 있습니다.
이에따라 모듈명을, 'module_project_gpt' 로 바꾸고,
configurations 의 app_conf.py 안의 server_name 만 project_gpt 로 바꾸면,

이처럼 모듈명을 바꾸어 실행시킬 수 있습니다.(실행 환경 설정시 작업 디렉토리 설정을 비워주는 것을 잊지 마세요.)
3. GPT 입출력 API 인터페이스 작성
Project GPT 의 핵심이 되는 LLM 모델을 적용하기 전에,
먼저 서버 컨트롤러단에서 LLM 모델에 질문을 보내고, 그 질문에 대한 응답을 받는 API 의 인터페이스부터 만들겠습니다.
인터페이스만 먼저 만들어 Swagger 에 공지 후, 구현은 나중에 해도 됩니다.
gpt_controller.py
from fastapi import APIRouter, Query, Response, Request
import module_project_gpt.models.gpt_model as model
import module_project_gpt.services.gpt_service as service
# [그룹 컨트롤러]
# Router 설정
router = APIRouter(
prefix="/gpt", # 전체 경로 앞에 붙는 prefix
tags=["API 요청 / 응답에 대한 테스트 컨트롤러"] # Swagger 문서 그룹 이름
)
# ----------------------------------------------------------------------------------------------------------------------
# <API 선언 공간>
@router.get(
"/get-gpt-response",
response_model=model.GetGptResponseOutputVo,
summary="Gpt 응답 요청 API",
description="GPT 모델에 질문하고 응답 받는 API",
responses={
200: {"description": "OK"}
}
)
async def get_gpt_response(
request: Request,
response: Response,
question: str =
Query(
...,
alias="queryParamString",
description="String Query 파라미터",
example="testString"
)
):
return await service.get_gpt_response(
request,
response,
question
)
GPT 응답을 요청하고 받는 API 는 위와 같이 gpt 컨트롤러에서 담당합니다.
출력값에 대한 OutputVO 의 모델은,
gpt_model.py
from pydantic import BaseModel, Field
# [그룹 모델]
# (Get 요청 테스트 (Query Parameter))
class GetGptResponseOutputVo(BaseModel):
class Config:
validate_by_name = True
gpt_response: str = (
Field(
...,
alias="gptResponse",
description="gpt 가 반환한 응답값",
examples=["testString"]
)
)
이러하고,
실질적인 비즈니스 로직을 담당할 gpt_service.py 는,
from fastapi import Response, Request
from fastapi.responses import JSONResponse
import module_project_gpt.models.gpt_model as model
# [그룹 서비스]
# (Gpt 응답 요청 API)
async def get_gpt_response(
request: Request,
response: Response,
query_param_string: str
):
return JSONResponse(
status_code=200,
content=model.GetGptResponseOutputVo(
gpt_response="todo" # todo
).model_dump()
)
이렇게 하였습니다.
위 컨트롤러를 실행시킨다면,
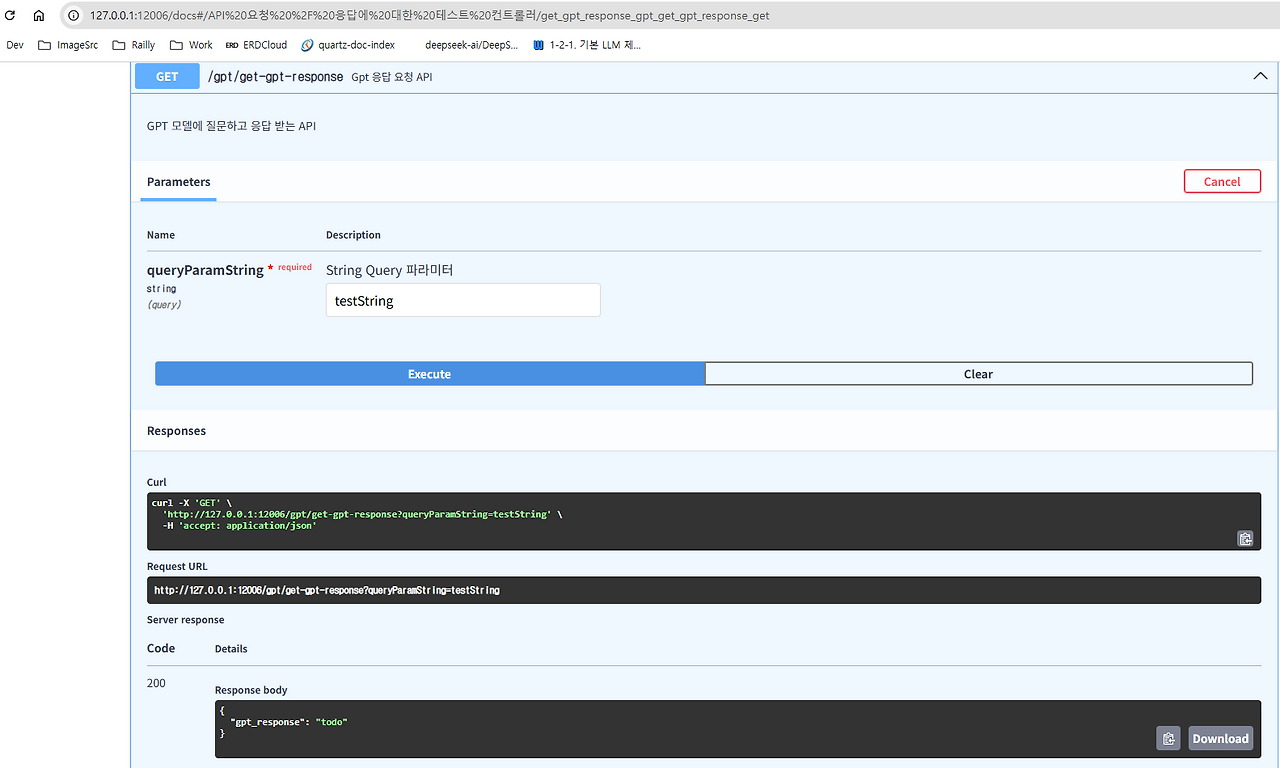
위와 같이 Swagger 문서상으로 인터페이스가 정상적으로 등록되고 더미 데이터도 잘 반환하는 것을 확인할 수 있습니다.
4. GPT 기능 추가
앞서 작성했던 LLM 모델(질문을 받으면 응답을 생성해주는 기능)을 적절한 위치에 배치하겠습니다.
비즈니스 로직은 당연히 Service 에 넣는 것이지만, 이 중에서도 GPT 관련 기능은 추후 개선의 여지가 있고, 잦은 변경이 예상되므로 적절히 파일 및 함수로 분할을 할 것입니다.
함수 설계는 아래와 같습니다.
1. LLM 모델의 가장 기본적인 인터페이스는 질문 입력, 응답 출력입니다.
2. LLM 객체의 생성은 생성 비용이 많이 들며, 시스템 전반에서 사용되는 요소이므로 전역 상수로 다룹니다.
3. GPT 모델을 객체지향적으로 정의하고 설계합니다.
4. VectorDB 를 이용한 검색 기능은 LLM 과 별개이므로 분리합니다.
처음은 간단히 진행하며, 추후 API 도, 함수 및 객체 구성도 절절히 리펙토링 하는 방식으로 진행합니다.
먼저, 기존 Langchain 프로젝트에서 LLM 모델로 사용한 Mistral 모델 파일을 새로 만든 서버 프로젝트로 복사합니다.
서버 프로젝트 구조상, 모듈 폴더 안에, 해당 모듈을 사용하기 위해 필요한 외부 파일을 저장하는 a_external_files 폴더가 존재하는데, 이 안에 모델 파일들을 복사하면 됩니다.

본 프로젝트에서 핵심이 되는 RAG 의 경우는 처음부터 고도화가 필요하므로, 먼저 GPT 모델부터 이식하겠습니다.
객체지향 설계는 놔두고 이를 util 함수로 다루겠습니다.
utils/gpt_util.py 를 만들고,
from langchain_community.llms import LlamaCpp
from langchain.prompts import PromptTemplate
import os
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
import module_project_gpt.configurations.app_conf as app_conf
# [벡터 DB 에 문서 내용이 저장된 상태에서 LLM 에게 질문]
# GGUF 모델 경로 설정
model_path = app_conf.module_folder_path + "/a_external_files/Mistral-7B-Instruct-v0.1-GGUF/mistral-7b-instruct-v0.1.Q2_K.gguf" # 모델 위치에 맞게 수정
# LlamaCpp 객체 생성
llm = LlamaCpp(
model_path=model_path,
n_gpu_layers=100, # GPU 사용
n_ctx=8000, # context size
temperature=0.7, # 창의성
max_tokens=1024, # 출력 길이
verbose=True
)
# 프롬프트 템플릿 설정
prompt = PromptTemplate(
input_variables=["question", "context"],
template="다음 문맥을 바탕으로 답변하십시오:\n{context}\n\n질문: {question}\n답변:"
)
# 체인 실행
chain = prompt | llm
# 임베딩 모델은 저장할 때 사용한 것과 동일한 것을 사용해야 함
embedding = HuggingFaceEmbeddings(model_name="intfloat/e5-base-v2")
if os.path.exists(app_conf.module_folder_path + "/by_product_files/my_vectorstore"):
# 저장된 벡터스토어 불러오기
vectorstore = FAISS.load_local(app_conf.module_folder_path + "/by_product_files/my_vectorstore", embedding,
allow_dangerous_deserialization=True)
async def request_to_gpt(question: str) -> str:
if vectorstore is not None:
docs = vectorstore.similarity_search(question, k=3)
else:
docs = []
context = "\n".join([doc.page_content for doc in docs])
result = chain.invoke({"question": question, "context": context})
return result
이렇게 기존 gpt 코드를 변환하였습니다.
참고로 여기서 객체지향 설계를 진행하지 않는 이유는, 이 부분이 현 시점에서 변경될 가능성이 큰 부분이기에 세부 설계를 하지 않고 테스트로 진행하게 하기 위해서입니다.
어쨌건 이렇게 한 상태에서, 기존 서비스 코드를,
async def get_gpt_response(
request: Request,
response: Response,
query_param_string: str
):
return JSONResponse(
status_code=200,
content=model.GetGptResponseOutputVo(
gpt_response=await gpt_util.request_to_gpt(query_param_string)
).model_dump()
)
이렇게,
실제로 llm 모델에게 문의하고 응답하도록 처리하면,

이전과 달리 서버 실행 시점에 LLM 모델이 메모리상에 올라가는 것을 로그로 확인하실 수 있습니다.
SwaggerAPI 로 이를 테스트하면,

이처럼 서비스가 잘 동작함을 볼 수 있습니다.