- 이번 포스팅에서는 CLIP 을 기반으로 발전한 이미지 내용 분석 및 자연어 생성 멀티 모달 모델인 BLIP 의 논문을 정리하겠습니다.
앞서 리뷰한 CoCa 모델에서 CLIP 을 기반으로 하여 이미지 캡셔닝, 비디오 내용 분석에 대한 새로운 접근 방식과 성능 향상 방법론을 배웠는데, BLIP 에서 발전한 BLIP-2 는 그보다 성능이 좋은 모델로 평가되므로 이전에 정리한 내용을 기반으로 어떤 방식으로 성능을 향상시켰는지를 파악할 수 있을 것입니다.
[BLIP]
- 논문 : BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (2022, salesforce)
(서론)
- VLP, Vision-Language Pre-training 은 이미지와 텍스트를 동시에 학습하는 사전 학습 기법을 의미합니다.
이러한 VLP 를 사용하여 다양한 작업에 활용하려고 했지만, 기존의 대부분의 사전 학습 모델은 분석과 생성이라는 두 작업으로 나누었을 때, 어느 한쪽에서만 뛰어난 성능을 보이고, 범용적으로 사용할 수 있는 모델은 없었다고 합니다.
게다가 CLIP 과 CoCa 설명에서 보았듯, 해당 모델의 학습 데이터 출처는 대부분이 웹 기반 수집 데이터인지라 잘못된 설명이나 무관한 테스트 쌍으로 구성되는 경우가 있었기에 데이터셋의 품질이 낮았다고 하네요.
본 논문에서는 BLIP 이라는 새로운 VLP 프레임워크를 제안합니다.
이는 비전-언어 이해 작업과 생성 작업 모두에 유연하게 적용되며,
Caption Bootstrapping 방식을 사용하여 잡음이 많은 웹 데이터를 효과적으로 활용하는 방식이라고 합니다.
Caption Bootstrapping 이란, 웹 데이터의 품질 낮은 캡션에 대응하기 위하여, 모델이 스스로 캡션을 생성하고, 질 나쁜 캡션을 필터링하는 방식으로 해결하는 방법이라고 하는데, 자세한 것은 아래에서 설명하겠습니다.
BLIP 모델의 성능을 먼저 간단히 소개하자면,
이미지-텍스트 검색 , 이미지 캡셔닝, VQA 등의 다양한 비전-언어 작업에서 기존 SOTA 모델 대비, +2.7%, +2.8%, +1.6% 의 성능 향상을 보였습니다.
또한 비디오-언어 작업에 zero-shot 으로 바로 적용해도 뛰어난 일반화 능력을 보여줬으며,
이에 대한 코드, 모델, 데이터셋을 논문에서 투명하게 공개합니다.
(소개)
- CLIP 이나 CoCa 와 같은 모델들을 필두로, 논문 게시 시점부터 비전-언어 사전 학습 모델이 다양한 멀티 모달 하위 작업에서 큰 성공을 거두고 있었다고 합니다.
하지만 기존 방식들은 두가지 큰 한계가 존재하는데,
1. 대부분의 방법론이 인코더 혹은 인코더-디코더 구조의 모델입니다.
인코더 모델은 텍스트 생성 작업으로 바로 사용하기 어렵고, 인코더-디코더 모델은 이미지-텍스트 검색 작업에 성공적으로 적용된 사례가 적습니다.
2. 대부분의 모델들이 웹 기반 수집 데이터셋을 사용합니다.
대규모 사이즈 확장으로 효과는 있지만, 여기서 발생하는 노이즈는 비전-언어 학습에 최선이 아닙니다.
- 위와 같은 이유로 인해 BLIP 을 만들었으며,
기존 방법보다 더 폭 넓은 다운스트림 작업에 적용이 가능한 VLP 프레임워크라고 소개하고 있습니다.
BLIP 은,
멀티 모달 인코더-디코더 혼합(Multimodal Mixture of Encoder-Decoder(MED))으로, 효과적인 사전 학습과 유연한 전이 학습을 지원하는 구조적 장점을 제공하는 새로운 모델 구조라고 하네요.
MED 가 처리할 수 있는 영역은, 단일 모달 인코더, 이미지 기반 텍스트 인코더, 이미지 기반 텍스트 디코더로 다양한 역할을 수행할 수 있는 효율적인 모델이며,
이러한 모델을 학습시키기 위해서는 이미지-텍스트 대조 학습, 이미지-텍스트 매칭, 이미지 조건 언어 모델링 3가지 비전-언어 목적 함수를 동시에 학습해야 합니다.

위 자료가 MED 의 구조를 나타냅니다.
왼쪽에는 Unimodal Encoder 로, 이미지와 텍스트 각각에 대한 인코더 모델들이 있습니다.
이미지 인코더는 ViT 구조이고, 텍스트 인코더는 BERT 처럼 보이네요.(둘 다 Self-Attention + FeedForward 이며, CLS 벡터를 다음 작업에 사용)
이와 같은 두 인코더를 학습시키는 것은, Image-Text Contrastive(ITC) 로 비슷한 이미지-텍스트 쌍은 가깝게, 다른 쌍은 멀게 학습시킵니다.
그 다음은 이미지 인코더 정보를 그대로 사용하여 텍스트 정보와 매칭하는 Image-Text Matching(ITM) Loss 를 사용하는 이미지-텍스트 쌍의 이진 분류(이미지 매칭, 검색) 모델입니다.
그리고 가장 우측의 모델은 이미지 정보를 기반으로 텍스트를 생성하는 이미지 캡셔닝 모델로,
이러한 세 모델을 한꺼번에 학습시켜 모든 하위 작업에서 일반화된 높은 성능을 보여주는 모델을 만드는 개념입니다.
CoCa 에서도 보았듯,
이 시기(CLIP 이 나온 시점인 2022년도) 딥러닝 모델은 다중 작업 학습을 통해 학습 방향을 제어하고 오버 피팅을 최소화하며 일반화된 모델을 만드는 기법이 활발하게 적용되는 것 같습니다.
사람 뇌도 한가지 작업만으로 학습되는게 아니라 살면서 얻는 무수한 피드백과 다양한 작업들을 수행하며 가장 최적의 형태로 학습되는 것과 같네요.
- Captioning and Filtering(CapFilt) 는, 캡셔닝과 필터링을 동시에 적용하여 웹 수집 데이터의 노이즈 문제를 해결하는 새로운 데이터셋 부트스트래핑 방식입니다.
사전 학습된 MED 를 웹 이미지에 대해 캡션을 생성하는 캡셔너와, 원본 웹 텍스트와 합성 텍스트 사이에서 잡음이 있는 캡션을 제거하는 필터의 두가지 모듈로 나누어 미세조정을 진행하는 방식이라고 가볍게 설명할 수 있습니다.

위와 같이 인터넷 상에서 가져온 캡션이 올바른건지 아닌지를 확인하는 Filt 모듈,
이미지를 기반으로 스스로 올바른 캡션을 생성하고, 그에 대해서도 올바른지를 확인하는 Filt 모듈의 구조이며,
캡셔너 모듈과 필터 모듈의 상호 협력이 모델 성능을 크게 높임을 증명했으며,
이로인한 더 다양한 캡션이 더 큰 성능 향상을 가져온다는 점도 발견했습니다.
- BLIP 은 이미지-텍스트 검색, 이미지 캡셔닝, 시각 질문응답, 시각 추론, 시각 대화 등 다양한 비전-언어 작업에서 최첨단 성능을 달성했다고 합니다.
또한 Zero-Shot 으로 별도 학습 없이도 SOTA 성능을 기록하여 뛰어난 일반화 능력도 입증했습니다.
(Related Work)
- VLP 는 대규모 이미지-텍스트 쌍을 사용하여 모델을 미리 학습시켜 이후 이를 응용하여 만들어지는 다양한 시각 및 언어 관련 작업 모델들의 성능을 향상시키는 것을 목표로 합니다.
- Knowledge Distillation
지식 증류라고 부릅니다.
이는, Teacher 모델의 지식을 Student 모델로 전달하여 학생 모델의 성능을 향상시키는 기법이고,
지식 증류 기법이 다양한 분야에서 좋은 성능 향상을 가져왔다고 합니다. (쉽게 설명하면, 잘 학습된 해당 분야에 정통한 교사 모델과 학습 모델이 동일한 입력값을 받으면 해당 분야에서 교사 모델의 출력값을 기반으로 학생 모델을 학습시키는 기법입니다.)
대부분의 기존 KD 기법이 학생 모델이 교사 모델과 동일한 클래스를 예측하도록 강제하는데,
본 논문의 KD 교사 모델이라고 할 수 있는 CapFilt 는 단순히 출력값이 일치하도록 학습하는 것이 아니라, 캡션 모델로 좋은 캡션을 생성하고, 나쁜 캡션을 필터 모델로 걸러내는 방식으로 KD 를 구현했습니다.
- CapFilt 의 캡션 생성 모델은 데이터 증강 방법이라고도 볼 수 있으며,
데이터 증강 기법은 컴퓨터 비전 분야에서는 이전부터 널리 사용되던 기법이지만 언어 작업에서는 그리 쉬운 일이 아니며, 본 논문에서는 이를 CapFilt 방식으로 적용하였다는 것을 알려줍니다.
(Method)
- BLIP 의 이미지 인코더는 ViT 를 사용합니다.
입력 이미지를 패치 단위로 나눈 후 임베딩 시퀀스로 변환하고, 전체 이미지 특징을 압축하기 위해 [CLS] 토큰을 추가하는 방식입니다.
기존의 CNN 백본 방식과 비교했을 때, ViT 가 계산 효율이 더 좋게 나오고 있으며, 이로 인해 최신 방법들에서도 채택되고 있기 때문이죠.
- 앞서 설명한 MED 에 대한 내용도 각 파츠별 설명합니다.
Unimodal Encoder 는, 이미지와 텍스트를 각각 따로 인코딩하며, 이미지 인코더는 ViT, 텍스트 인코더는 BERT 와 동일하며, 전체 의미 요약을 위해 텍스트 맨 앞에 [CLS] 토큰을 붙이는 방법론을 따릅니다.
Image 기반 Text Encoder 는, 텍스트 인코더의 Transformer 블록에서 self-attention 과 feed-forward 레이어 사이에 cross-attention 을 추가하여 시각 정보와의 정보 융합을 하였습니다.
Image 기반 Text Decoder 는, 이미지 기반 텍스트 인코더와 구조적으로 유사한데, 디코더 특성상, 미래 토큰을 못 보도록 마스킹을 한 self-attention 을 사용했다고 합니다.(Transformer 정리글을 참고하세요.)
- 사전 학습 목표는,
1. Image-Text Contrastive Loss(ITC) :
CLIP 방식의 서로 다른 주제의 단일 모달 결과 벡터를 동일 의미에 투영하는 방식,
이미지와 텍스트 특징 공간을 정렬 시키는 역할
2. Image-Text Matching Loss(ITM) :
이미지-텍스트 쌍이 맞는지 일치 여부를 예측하는 이진 분류
3. Language Modeling Loss(LM) :
이미지 정보를 기반으로 텍스트를 생성
위와 같은 모든 Loss 를 동시에 최적화하는 방식으로 진행됩니다.
- CapFilt 는, 고품질의 이미지-텍스트 쌍을 만드는 작업은 높은 비용 때문에 그 수가 제한적인데,
최신 연구 모델들은 웹에서 자동으로 수집한 이미지-텍스트 쌍의 데이터셋을 사용하여 데이터 스케일로 품질을 덮는 방식을 사용하고 있었습니다.
그러나 CLIP, CoCa 에서도 언급했듯, 이러한 방식이 편향적 의미를 모델에 주입시키거나, 잘못된 내용을 전파하므로 학습 품질을 떨어뜨린다고 합니다.
본 논문에서 제안하는 CapFilt 는 이를 해결하기 위한 방법이며,
웹 이미지를 주면 캡션을 생성하는 캡셔너 모델, 잡음이 있는 이미지-텍스트 쌍을 판별하며 제거하는 필터 모델로 이루어져 웹 수집 데이터의 품질을 높이는 기법입니다.
캡셔너와 필터는 동일한 사전 학습된 MED 모델에서 초기화되며, COCO 데이터셋을 사용하여 각각을 파인튜닝 합니다.
- CapFilt 의 각 요소들의 동작들에 대해 설명하겠습니다.

1. Captioner 동작 : 캡셔너는 이미지 기반의 텍스트 디코더라고 할 수 있습니다.
이미지를 기반으로 텍스트를 생성할 수 있도록 LM Loss 함수로 파인튜닝 되며,
웹 이미지 lw 가 주어지면 이미지당 하나의 합성 캡션 Ts 를 생성하는 역할을 합니다.
2. Filter 동작 : 필터는 이미지 기반의 텍스트 인코더라고 할 수 있습니다.
텍스트와 이미지가 상호 짝이 맞는지 판단하도록 ITC 와 ITM Loss 함수로 파인토닝되며,
원래의 웹 텍스트 Tw 와 합성 텍스트 Ts 모두에서 잡음을 제거하며, ITM 헤드가 이미지와 불일치한 텍스트를 잡음으로 간주하여 제거하는 역할을 합니다.
- CapFilt 로 필터링된 이미지-텍스트 쌍과 사람 주석 데이터쌍을 결합하여 새로운 데이터셋을 만들고, 이를 사용하여 새로운 모델을 사전 학습하는 방식을 사용했다고 합니다.
(Experiments and Discussions)
- 본 섹션에서는 사전 학습 세부 사항과 제안한 방법에 대한 상세한 실험 내용에 대한 분석을 공유합니다.
- 실험 환경
1. BLIP 모델은 PyTorch 로 구현되었고, 16개의 GPU 를 가진 2개 노드(총 CPU 32 장 사용)에서 사전학습하였습니다.
2. ViT 는 ImageNet 으로 사전학습된 모델을 사용하며, 텍스트 트랜스포머는 BERT 사전 학습 모델을 사용했습니다.
3. Vit-B/16, ViT-L/16 두가지 변형을 실험했습니다.
논문상 별도 언급이 없다면 ViT-B 의 결과입니다.
4. BLIP 모델은 20에폭으로 사전학습하며, 배치 크기는 ViT-B 의 경우 2880, ViT-L 의 경우 2400 입니다.
제가 개인 컴퓨터로 작은 크기의 비전 모델을 학습 시킬 때의 배치 크기가 8에서 12 정도인데, GPU 를 32장이나 사용할 정도로 엄청난 스케일입니다.
5. 학습 옵티마이저는 AdamW 이며, Weight decay 값은 0.05 입니다.(AdamW 는 Adam 의 변형으로, L2 정규화를 사용하여 더 안정적입니다.)
6. 학습률은 ViT-B 의 경우 3e-4, ViT-L 은 2e-4 까지 워밍업 한 후, 0.85 비율로 선형 감소시킵니다.
7. 사전 학습 중에는 해상도를 224x224 의 랜덤 이미지 크롭 방식을 사용하고, 파인튜닝 시에는 384x384 로 높이는 식으로, 처음에는 작은 해상도로 빠른 학습, 이후 세밀한 정보를 학습하는 방식을 사용하였습니다.
8. 데이터셋은 COCO, Visual Genome 과 같은 고품질 사람 주석 데이터를 포함하여, 그외에는 대규모 웹 데이터로 혼합 구성을 하였습니다.
또한, 1억 1500만 개의 대규모 웹 데이터셋 LAION 도 실험에 사용하였고, LAION 은 사이즈만큼 노이즈도 많은 데이터이기에 CapFilt 방식으로 필터링 하여 적용했습니다.
- CapFilt 의 효과

Table1 에서는 서로 다른 데이터셋으로 사전 학습된 모델들을 비교한 결과를 보여줍니다.
CapFilt 가 다운스트림 작업에 미치는 영향을 볼 수 있는데,
캡셔너 C 와 필터 F 의 적용 여부에 따른 성능 변화를 보면 둘 중 하나만 적용해도 성능이 향상되는 것을 볼 수 있습니다.
둘을 함께 적용하면 상호 시너지로 인해 원래의 노이즈 데이터 대비 성능이 크게 향상한 것을 볼 수 있네요.
데이터의 크기, 모델의 크기가 더 커질수록 CapFilt 의 효과가 더 커지는 것도 볼 수 있습니다.

Figure 4 는 캡셔너/필터 적용 예시입니다.
Tw 는 원래 웹에서 가져온 캡션, Ts 는 캡셔너가 생성한 캡션, 녹색은 필터가 채택한 캡션, 빨간색은 필터가 제거한 캡션입니다.
예시를 보면 원래 웹 텍스트보다 구체적이고 시각 정보와 걸맞는 캡션이 생성 된 것을 볼 수 있습니다.
Table 2 는 캡셔너 생성 방식을 비교한 테이블입니다.
다음 단어 선택 방식에 따라 실험한 결과인데,
Beam Search 방식과 Nucleus 방식 중 Nucleus 방식이 더 효과적이었단 것을 보여줍니다.
잠시 설명하자면,
Beam Search 방식은,
다음 단어 하나만 보고 결정하는게 아니라 여러 후보 경로를 동시에 탐색해 가장 높은 전체 확률을 가진 문장을 찾는 방법입니다.
일반적인 방식은, Greedy Search 방식으로, 매 단계마다 가장 확률이 높은 단어 하나만 고르는 것인데, 이렇게 되면 한번 잘못된 선택을 하면 돌아갈 수 없이 전체 문장이 이상해지므로,
Beam Search 는 이를 보완하여 매 단계에서 상위 N개의 후보 경로를 유지하고 확장하며, 전체 확률이 가장 높은 문장을 찾는 것입니다.
예를 들어, Beam Size 가 3 이면 3개의 상위 후보를 선택하는 것이고,
<BOS> 다음에 올 세 후보가
<BOS> → "I"(0.4), "You"(0.35), "He"(0.25)
위와 같이 나왔다고 합시다.
다음에 이를 확장할 때에는,
"I" → am(0.5), love(0.3), eat(0.2)
"You" → are(0.6), love(0.25), run(0.15)
"He" → is(0.7), runs(0.2), eats(0.1)
위와 같이 이전 세 후보의 각각에 대해 또다시 세 후보를 구한 후,
각 후보의 누적 확률로, 이전까지의 확률 * 이번 단어의 확률을 계산하여,
"I am" → 0.4 × 0.5 = 0.20
"I love" → 0.4 × 0.3 = 0.12
"You are" → 0.35 × 0.6 = 0.21
...
이렇게 하는 것입니다.
다음에는 I am, I love, You are 을 기반으로 또 다음에 올 각 3개의 단어들을 선정해 누적 확률 계산을 진행하는 식으로 진행하죠.
이렇게 하면 보다 느려지기는 하지만, 전반적으로 높은 성능의 문장을 만들어 낼 수 있게 됩니다.
다음으로 Nucleus Sampling 은,
다음 단어 전체 확률 분포에서 확률이 누적합으로 p 이상이 될 때까지 상위 단어 집합을 선택하고, 그 집합 내에서 확률에 따라 랜덤하게 단어를 선택하는 방식입니다.
p 값이 작으면 제한적인 선택이 되는거고, 크면 다양한 표현이 되는 것이죠.
이는 창의적이고 자연스러운 문장 생성이 가능한 방식으로, Beam Search 방식보다 빠르다는 장점이 있지만, 다른 방식들보다 품질이 일정하지 않을 수도 있고, 무작위성이 있어 결과가 매번 변할 수 있다는 단점이 있습니다.
예를 들어, p 가 0.9 라고 할 때,
"runs"(0.4), "jumps"(0.3), "walks"(0.2), "flies"(0.05), "sleeps"(0.05)
다음 단어의 후보와 확률이 위와 같다면,
상위 확률값부터 누적해나가면 0.4 + 0.3 + 0.2 로 하여 0.9 가 되므로 runs 에서 walks 까지를 한 집합으로 선택하고, 이 내에서 랜덤으로 뽑는 방식입니다.
위에서 설명했듯, BLIP 의 캡셔너의 생성 방식은 Nucleus Sampling 방식이 더 효과적이었다고 하네요.
Table 3 는 사전학습시 텍스트 인코더 & 디코더의 일부 레이어를 공유하는 것에 대한 실험 결과입니다.
None 은 공유를 하지 않는 기본 성능이고,
Cross Attention 가중치 공유, Self Attention 가중치 공유, 전부 가중치 공유의 옵션이 있는데,
전부 공유가 가장 성능이 낮고,
SA 공유는 오히려 기본 성능보다 성능이 높아질 수 있음을 볼 수 있습니다.
논문에서 사용한 Nucleus 샘플링의 p 값은 0.9 입니다.
(SOTA 모델과의 성능 비교)
- 5 섹션에서는 기존 SOTA 모델과의 성능 비교에 대해 적혀있습니다.
BLIP 모델을 COCO 와 Flickr30k 데이터셋에서 이미지 -> 텍스트 검색(TR)과 텍스트 -> 이미지 검색(IR) 두가지 과제로 평가했습니다.
사전 학습된 모델을 ITC, ITM 손실 함수로 미세 조정을 하였고,
추론 속도를 빠르게 하기 위해, 먼저 이미지-텍스트 특징 유사도에 기반해 후보 k 개를 선택하고, 그 후보들을 ITM 점수로 다시 순위 매기는 2단계 방식을 적용했습니다.
COCO 에서는 후보수 k=256, Flikr30k 에서는 k=128 을 사용했습니다.
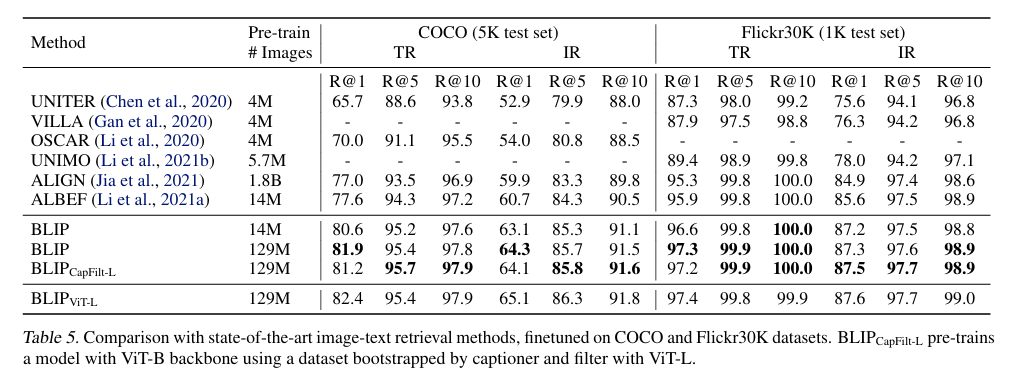
Table 5 결과로 BLIP 이 기존 SOTA 에 비해 상당한 성능 향상을 기록한 것을 볼 수 있습니다.(굵은 숫자입니다. 무려 100 이나 99 까지도 되네요...)
같은 1400만장의 사전학습 데이터로, COCO 데이터셋에서 평균 R@1 성능이 이전 최고 모델인 ALBEF 보다 2.7%나 높게 나왔습니다.
또한 COCO 에서 미세조정한 모델을 그대로 Flickr30k 에 적용하는 제로샷 검색도 실행했다고 하네요.

이것이 그 결과이며,
보시다시피 제로샷 성능마저도 기존 모델보다 크게 앞서는 것을 보여줍니다.
이는 BLIP 의 일반화 성능이 특화 모델 수준 이상으로 올랐다는 것을 증명합니다.
- 이미지 캡셔닝 성능 비교는,
COCO, NoCaps 두 데이터셋을 COCO 데이터셋으로 파인튜닝한 모델로 비교하였습니다.
프롬프트는 'a picture of' 라는 접두어를 붙였고, 이러한 프롬프트 방식이 결과를 약간 향상시키는 것을 확인했습니다.

Table7 이 결과표이며, 이 역시 BLIP 과 비슷한 규모의 다른 모델들 보다 훨씬 좋은 성능을 내는 것을 볼 수 있습니다.
1억 2900만개의 이미지를 사전학습한 BLIP 이 2억개의 이미지를 사전학습한 LEMON 과 비슷한 성능을 내어 효율성을 확인했으며, 또한 LEMON 이 800x1333 의 고해상도 입력 이미지를 사용(사전 학습된 객체 탐지기에서 요구)하여 추론 속도가 크게 느려지는 반면, BLIP 은 객체 탐지기를 사용하지 않는 구조이며, 384x384 의 이미지를 사용하여 더 빠른 추론이 가능합니다.
- 시각 질의 응답(VQA) 은 모델이 이미지와 질문을 입력받아 정답을 예측하는 과제입니다.
기존에는 미리 정의된 답변 후보중 하나로 분류하는 방법론을 사용했지만, BLIP 은 모델이 직접 텍스트를 생성하기에 훨씬 유연한 개방형 VQA 를 구현했습니다.

위 자료의 a 에서 보이는 방식으로 아키텍쳐를 구성하였으며, 먼저 이미지-질문 쌍을 멀티모달 임베딩으로 인코딩 한 후, 이를 답변 디코더에 전달하는 방식입니다.
이리하여 VQA 모델은 정답을 타겟으로 하여 LM Loss 로 파인튜닝하며, 그 결과,
높은 성능을 기록했습니다.
보다 어려운 자연어 생성 방식으로 분류 모델을 성능으로 이긴 것과,
SimVLM 의 경우 13배나 더 많은 학습 데이터와 더 큰 비전 백본을 사용하는데도 성능 우위를 점했다는 것을 증명합니다.
- 위 figure 5 에 나온 모델들의 아키텍쳐를 보면,
NLVR2 와 VisDial 모델이 있는데, 이 역시 BLIP 으로 응용 가능한 모델이며, 이에 대한 성능 비교도 있습니다.
NLVR2 는 Natural Language Visual Reasoning 으로, 자연어 시각 추론은 한 문장이 두장의 이미지를 설명하는지를 예측하는 과제입니다.
예를들어 두장의 이미지가 주어지고, 문장이 "왼쪽 이미지는 고양이 사진이고, 오른쪽 이미지는 강아지 사진이다" 라고 했을 때 True or False 를 잘 나누는지를 보는 것이죠.
구조에 대한 자세한 설명은 생략하고,
BLIP NLVR2 가 기존 모델들의 성능을 능가하는 우수한 성능을 보여줬는데,
맞춤형 사전 학습을 추가로 수행한 ALBEF 를 제외한 모든 기존 방법보다 뛰어난 것으로 보아, 특별한 추가 학습 없이도 BLIP 이 대부분의 모델을 능가합니다.
NLVR2 실험의 흥미로운 점으로는, 이 작업에 대해서는 웹 이미지를 더 사용하여 학습하더라도 성능이 더이상 향상되지 않는다고 합니다. 이는 웹 데이터와 다운스트림 데이터간의 도메인 차이 때문일 수도 있으며, 일반화 모델의 한계일 가능성도 있겠네요.
다음으로 VisDial 은 VQL 을 확장하여 자연스러운 대화 환경에서 수행되는 과제입니다.
여기서 모델은 이미지-질문 쌍 뿐만이 아니라 대화 기록(대화 맥락)과 이미지 캡션까지 고려하여 답변을 예측해야 합니다.
이에 대해서는 생성형 방식이 아니라, 여러 후보 답변 중에서 가장 적절한 순서로 순위화를 하는 방식을 사용하였으며,
figure5 의 c 에서 보이듯, 이미지 임베딩과 캡션 임베딩을 연결한 후, 이를 Cross Attention 을 통해 Dialog 인코더에 전달하여 true/false 를 반환하도록 했습니다.
대화 인코더는 ITM 손실로 학습되며, 주어진 전체 대화 기록과 이미지-캡션 임베딩을 기반으로 답변이 질문에 대해 참인지 거짓인지를 구분하는 작업을 수행합니다.
성능 결과, VisDial v1.0 검증 세트에서 SOTA 를 달성했습니다.
- 이외에 BLIP 모델이 zero-shot 으로 비디오-언어 작업에 적용했을 때의 성능을 실험한 결과가 공유되었는데,
당연히 높은 성능을 보였으며, 이는 프레임 단위 시각 이해와 언어 이해 능력이 강하다는 의미입니다.
결론을 내리면, BLIP 모델이 영상 데이터 학습이 없이도 영상 검색과 영상 기반 질문응답에서 기존 모델 성능을 크게 초월하였고, 이에 시간 정보를 다루는 기능을 개선하면 추가적인 성능 향상이 예상되는 상황입니다.
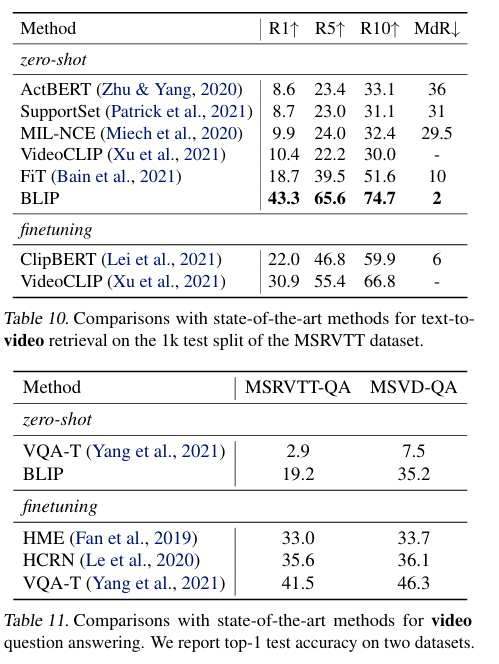
위의 성능표를 보시면 비디오 관련 작업에서 BLIP 이 얼마나 압도적인 성능인지를 확인할 수 있습니다.
- 여기까지 하여 BLIP 첫번째 버전의 논문 리뷰가 끝났습니다.
BLIP 은 버전 2까지 발전하였으므로 모델에 대한 파이토치 코드는 BLIP-2 에서 구현 후 리뷰하겠습니다.
'Study > Computer Vision' 카테고리의 다른 글
| [Android] JNI 사용 방법 정리(Java 에서 C++ 언어를 사용하는 방법) (0) | 2025.10.15 |
|---|---|
| [Android] 모바일 딥러닝, TFLite 사용법 정리(모바일 이미지 분류기 구현) (0) | 2025.10.15 |
| [딥러닝] CoCa(Constrastive Captioners) 모델 논문 리뷰(CLIP 기반 자연어-이미지 임베딩 모델, 이미지 캡셔닝, 비디오 내용 분석) (2) | 2025.08.08 |
| [딥러닝] CLIP(Contrastive Language-Image Pre-training) 논문 리뷰 (멀티모달 임베딩 기술) (3) | 2025.08.08 |
| [딥러닝] BiSeNet V2 (Semantic Segmentation, 파인 튜닝 및 개발 방법, 논문 해석) (4) | 2025.08.03 |