- 이번 포스팅으론 머리를 식히는 개념으로, 이제까지 배운 컴퓨터 비전 지식을 실제 서비스로 만들어보는 시간을 가지도록 하겠습니다.
이전 글들은 전부 날아간 상태이므로, 추후 관련된 컴퓨터 비전 관련 지식들은 다시 정리할 것입니다.
- 구현할 기능은, 영상 데이터를 받아서, 얼굴을 탐지하고, 해당 얼굴이 누구인지를 식별하도록 하는 것입니다.
(동영상, 카메라의 실시간 분석도 가능)
식별된 구역을 바운딩박스로 묶어주고,
탐지 결과를 출력 및 엑셀 파일로 저장을 해줍니다. (영상 인식 출입 통제의 가장 기본적인 기능)
- 개발 시작
0. 준비
라이브러리 컴파일을 위해 비주얼 스튜디오 C++ 개발을 설치하시고,
파이썬 최신버전(64bit여야 합니다.)에, 파이참 커뮤니티 버전을 설치하시면 됩니다.
cmake도 설치해둡시다.(cmake는 파이참에서도 설치할텐데, 보험으로 설치해두세요.)
일단 파이참에서 새 프로젝트를 생성합시다.
그리고 사진 비교를 위해 빌게이츠 사진과 일론머스크 사진을 검색해서 받아두세요.
아니면 좋아하는 연예인 사진도 각자 다른 인물로 준비합시다.
이제 face recognition을 실행시키기 위한 종속성 라이브러리를 설치해야합니다.(해당 라이브러리가 내부적으로 사용하는 다른 라이브러리들)
파이참에서는 쉽게 설치가 가능한데,
file - setting - project:프로젝트명 - project Interpreter에 들어가서, 인터프리터를 설정하고, +를 누르면, 검색창이 나옵니다.
거기에서,
pip, cmake, numpy, opencv-python, dlib(이건19.18버전으로 설치), face-recognition(Adam Geitgey)
을 검색해서 설치해줍시다.
dlib과 face-recognition은 파이썬 최신버전의 64비트에서만 설치 가능합니다.
또한 위에서 설치한 C++ 관련 개발 툴이 필요합니다.
정확히는 컴파일러가 필요한 것으로,
컴파일 개념은 제쳐두고,
원래 opencv와 같은 라이브러리를 사용하려면 컴파일해서 사용할수 있는 형태로 만들어야하는데,
파이참이 자체적으로 라이브러리를 설치할때, c++에서 우리가 설치한 cmake와 같은 것으로 컴파일을 실행시켜준다고 생각하면 됩니다.(비주얼 스튜디오 컴파일러에게, 이런것좀 처리해줘 라고 요청하는 것이죠. 만일 C++ 개발에서, opencv나 다른 라이브러리 사용하려면, 직접 cmake로 설정하고 컴파일을 해줘야합니다.)
1. 라이브러리 테스트
종속성 설정이 잘 되었는지 보기 위해 몇가지 테스트를 해봅니다.
먼저 프로젝트 아래에 ImageBasic이란 디렉토리를 만들고, 그 안에 빌게이츠 사진과 일론머스크 사진을 넣어줍니다.(사진은 각각 동일 인물 다른 사진으로 다수 확보해둡시다.)
프로젝트 바로 아래에 Basic.py라는 새 파이썬 파일을 생성하고 아래와 같이 작성합니다.
import cv2
import numpy as np
import face_recognition
imgElon = face_recognition.load_image_file('ImageBasic/Elon_Musk_2015.jpg')
imgElon = cv2.cvtColor(imgElon, cv2.COLOR_BGR2RGB)
imgBill = face_recognition.load_image_file('ImageBasic/454px-Bill_Gates_2014.jpg')
imgBill = cv2.cvtColor(imgBill, cv2.COLOR_BGR2RGB)
cv2.imshow('Elon Musk', imgElon)
cv2.imshow('Bill Gates', imgBill)
cv2.waitKey(0)
우리가 설정한 인터프리터로 잘 실행이 되는지 확인하면 됩니다.
이상없이 각 사진의 창이 뜨면,
opencv, numpy, face_recognition 모두 클리어한 것이고,
나머지 종속성 라이브러리도 잘 설치된 것이니 마음놓고 개발이 가능합니다.
혹시 저 코드 해석이 필요한 분이 있을지 몰라 덧붙이자면,
위의 코드는, face_recognition으로 하드웨어의 이미지를 불러오고, opencv로, 각 이미지의 컬러 채널 순서를 바꾸는 것이며, 마지막으로 각 변수로 메모리에 올라온 이미지를 imshow로 출력해준 것입니다.
파이썬 코딩 자체가 낯서신 분은, 관련 영상이 유튜브에 많으니 추천드리고, 넘파이, opencv에 대해서도 잘 정리된 자료를 공부하시면 이해가 더 쉬울 것입니다.
face_recognition은 여기에서 제공해주는 얼굴 인식 라이브러리로, 딥러닝과 dlib이 같이 쓰여서 만들어진것 같은데, 나중에 비슷하게라도 구조를 정리해봐야겠고, dlib은 얼굴 인식에 가장 많이 사용되는 특징점 추출 알고리즘으로, 이에 대해선 근시일내 정리 예정.
2. 얼굴 찾아보기
얼굴 탐지입니다.
보라색 사각형으로 얼굴이 있는 위치의 바운딩 박스를 표시해줍니다.
import cv2
import numpy as np
import face_recognition
imgElon = face_recognition.load_image_file('ImageBasic/Elon_Musk_2015.jpg')
imgElon = cv2.cvtColor(imgElon, cv2.COLOR_BGR2RGB)
imgBill = face_recognition.load_image_file('ImageBasic/454px-Bill_Gates_2014.jpg')
imgBill = cv2.cvtColor(imgBill, cv2.COLOR_BGR2RGB)
faceLoc = face_recognition.face_locations(imgElon)[0]
encodeElon = face_recognition.face_encodings(imgElon)[0]
cv2.rectangle(imgElon, (faceLoc[3], faceLoc[0]), (faceLoc[1], faceLoc[2]), (255, 0, 255), 2)
cv2.imshow('Elon Musk', imgElon)
cv2.imshow('Bill Gates', imgBill)
cv2.waitKey(0)
위의 테스트 코드를 그대로 사용하는데,
faceLoc으로, face_recognition이 검출한 얼굴의 위치를 가져옵니다. 처음것만 가져오는데,
한 이미지에 사람이 많다면, 각각의 구역에 대한 위치가 반환됩니다.(안면 검출에 대해서는, 이전에 정리한 것 같기도 한데, 각 구역별 특징데이터를 추출하여, 얼굴에서 많이 나오는 특징을 많이 보유한 구역이 점수가 가장 많이 나올것이므로, 점수가 높은 구역을 추려내는 형식입니다.)
위치 정보가 나왔으니, 분류 정보도 나와야겠죠.
face_encoding은, 우리가 검출한 얼굴 구역 내에, 더 세밀하게 등장하는 특징들을 모아서 인코딩한 것입니다.
사람마다 얼굴 특징이 있겠죠.
그 특징을 많이 보유한다면 영상으로 그 사람이라고 알수 있는 것입니다. 바로 이러한 정보를 담고있는 정보를 출력해주는 것으로, 우리가 앞으로 이 인코딩 데이터에 이름을 붙이면, 비슷한 유형... 이 인코딩 데이터의 특징이 잘 나타나는 다른 사진들도 해당 인물이라고 학습하여 예측하게 되는 것입니다.(인코딩이라고 하니 내부는 인코더 디코더 모델로, 비지도 학습을 사용했네요. 이제 이 인코딩 데이터로, 우리가 누구라고 학습을 시켜주면 됩니다.)
일단은 위치 정보만 위와 같이 사각형 바운딩 박스로 표현해주고 확인하면 됩니다.
3. 동일인 판명
import cv2
import numpy as np
import face_recognition
#===이미지 로드===
imgElon = face_recognition.load_image_file('ImageBasic/Elon_Musk_2015.jpg')
imgElon = cv2.cvtColor(imgElon, cv2.COLOR_BGR2RGB)
imgElon_test = face_recognition.load_image_file('ImageBasic/Elon_Musk_Royal_Society.jpg')
imgElon_test = cv2.cvtColor(imgElon_test, cv2.COLOR_BGR2RGB)
imgBill = face_recognition.load_image_file('ImageBasic/454px-Bill_Gates_2014.jpg')
imgBill = cv2.cvtColor(imgBill, cv2.COLOR_BGR2RGB)
#===이미지 분석===
# 일론머스크
faceLoc = face_recognition.face_locations(imgElon)[0]
encodeElon = face_recognition.face_encodings(imgElon)[0]
cv2.rectangle(imgElon, (faceLoc[3], faceLoc[0]), (faceLoc[1], faceLoc[2]), (255, 0, 255), 2)
# 일론머스크 테스트
faceLocTest = face_recognition.face_locations(imgElon_test)[0]
encodeElonTest = face_recognition.face_encodings(imgElon_test)[0]
cv2.rectangle(imgElon_test, (faceLocTest[3], faceLocTest[0]), (faceLocTest[1], faceLocTest[2]), (255, 0, 255), 2)
#빌게이츠
faceLocBill = face_recognition.face_locations(imgBill)[0]
encodeBill = face_recognition.face_encodings(imgBill)[0]
cv2.rectangle(imgBill, (faceLocBill[3], faceLocBill[0]), (faceLocBill[1], faceLocBill[2]), (255, 0, 255), 2)
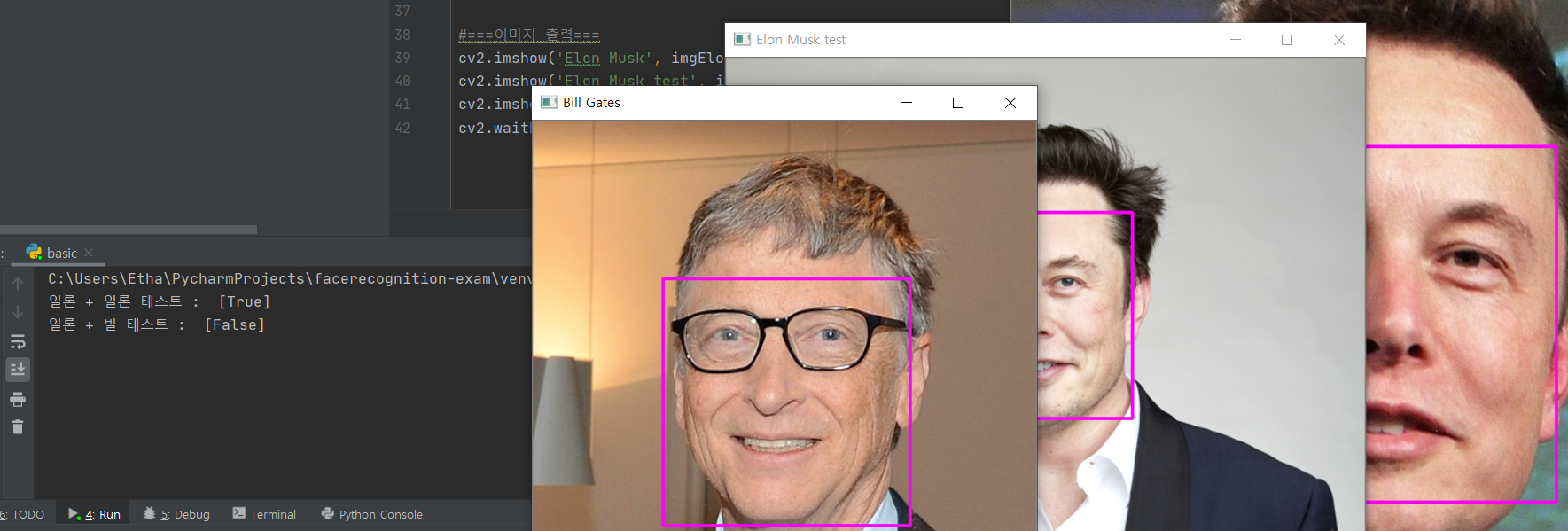
#===일치 결과 비교===
results1 = face_recognition.compare_faces([encodeElon], encodeElonTest)
results2 = face_recognition.compare_faces([encodeElon], encodeBill)
print('일론 + 일론 테스트 : ', results1)
print('일론 + 빌 테스트 : ', results2)
#===이미지 출력===
cv2.imshow('Elon Musk', imgElon)
cv2.imshow('Elon Musk test', imgElon_test)
cv2.imshow('Bill Gates', imgBill)
cv2.waitKey(0)
서로 다른 일론머스크 사진을 2장 준비합니다.
그리고 각자 face_recognition으로 인코딩 데이터를 가져옵니다.
인코딩 데이터에는 해당 얼굴이 지니는 독특한 패턴이 추출되어 나옵니다.
이것이 비슷한 패턴을 지닐때, 두 사진은 동일인물입니다.
Test 일론머스크와 그냥 일론머스크 사진에서 나온 인코딩 데이터를 비교하면 되는데,
이 역시 제공해준다고 합니다.
compare을 위와 같이 하면, results가 반환되는데,
확인해보면, 동일인물 사진이라면 True가 나오고 아니면 False가 나옵니다.
이제 슬슬 구조가 보이네요.
안면인식을 하고싶으면, 데이터베이스에 이러한 인코딩 정보를 저장해두고, 서로 비교하여 True가 나오는지를 비교하여 판단하면 됩니다.
4. 거리 파악
데이터 분류에서, 계산과정에서 그 일치도를 얻어낼수 있는데,
그것을 일종의 거리 개념으로 생각하시면 됩니다.
거리가 가까우면 서로 비슷하다는 것이고, 거리가 멀면 서로 멀다는 뜻이죠.
#===일치 결과 비교===
results1 = face_recognition.compare_faces([encodeElon], encodeElonTest)
results2 = face_recognition.compare_faces([encodeElon], encodeBill)
faceDis1 = face_recognition.face_distance([encodeElon], encodeElonTest)
faceDis2 = face_recognition.face_distance([encodeElon], encodeBill)
print('일론 + 일론 테스트 : %s (%f%%)' %(results1, 1-faceDis1))
print('일론 + 빌 테스트 : %s (%f%%)' %(results2, 1-faceDis2))
결과 비교 코드에 위와 같이, face_distance를 구해주면, 각자 거리에 대한 실수값이 출력됩니다.
이는 손실율의 개념이므로, 일치도를 확인하려면 위와 같이 1을 빼주어서 일치 확률을 얻어낼수 있습니다.
5. 캠 화면 얼굴 인식
조금 더 실용적인 얼굴 인식을 해봅시다.
해당 라이브러리는 식별 가능한 인코딩 분석 데이터를 추출할수 있고,
해당 데이터끼리 비교하여 거리를 구할수 있습니다.
이러한 것을 이용해서 캠으로 얼굴을 받고, 일치하는 얼굴을 찾아내는 것입니다.
import cv2
import numpy as np
import face_recognition
import os
# 설정
path = 'ImageBasic'
images = []
classNames = []
myList = os.listdir(path)
# 사진 디렉토리 내 이미지 경로 리스트 추출
for cl in myList:
curImg = cv2.imread(f'{path}/{cl}')
images.append(curImg)
classNames.append(os.path.splitext(cl)[0])
print(classNames)
# 각 사진별 인코딩 함수
def find_encodings(image_paths):
encode_list = []
for image_path in image_paths:
inner_image = cv2.cvtColor(image_path, cv2.COLOR_BGR2RGB)
encode = face_recognition.face_encodings(inner_image)[0]
encode_list.append(encode)
return encode_list
# 인코딩 리스트 받기
encodeListKnown = find_encodings(images)
print(f'Encoding Complete {len(encodeListKnown)}')
# 캠 영상 받아서 처리
cap = cv2.VideoCapture(0)
while True:
success, cap_img = cap.read()
imgS = cv2.resize(cap_img, (0, 0), None, 0.25, 0.25)
imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB)
# 캠 얼굴 인코딩
faceCurFrame = face_recognition.face_locations(imgS)
encodesCurFrame = face_recognition.face_encodings(imgS, faceCurFrame)
# 캠 얼굴과 메모리상 인코딩 데이터간의 비교
for encodeFace, faceLoc in zip(encodesCurFrame, faceCurFrame):
matches = face_recognition.compare_faces(encodeListKnown, encodeFace)
faceDis = face_recognition.face_distance(encodeListKnown, encodeFace)
matchIndex = np.argmin(faceDis)
if matches[matchIndex]:
name = classNames[matchIndex].upper()
y1, x2, y2, x1 = faceLoc
y1, x2, y2, x1 = y1*4, x2*4, y2*4, x1*4
cv2.rectangle(cap_img, (x1, y1), (x2, y2), (0,255,0),2)
cv2.rectangle(cap_img, (x1, y2-35), (x2, y2), (0,255,0), cv2.FILLED)
cv2.putText(cap_img, name, (x1+6, y2-6), cv2.FONT_HERSHEY_COMPLEX, 1, (255,255,255), 2)
cv2.imshow('cam', cap_img)
cv2.waitKey(1)
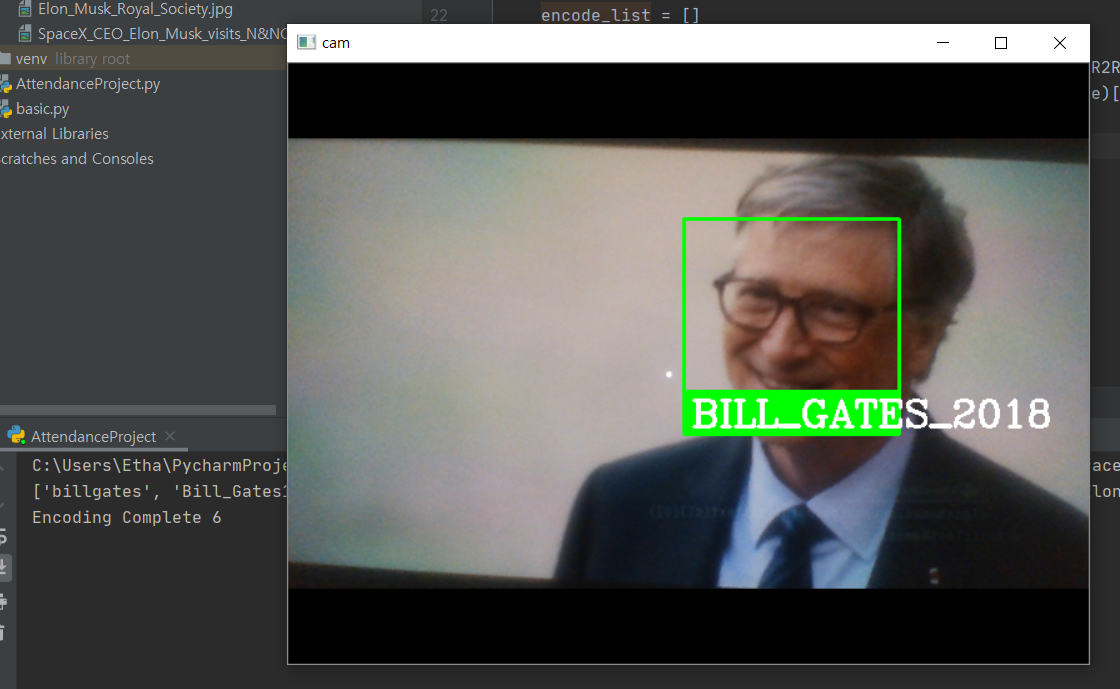
캠 인식 결과는 위와 같습니다.(빌게이츠의 프린팅된 사진을 사용해서 실시간으로 인식한 것입니다.)
인코딩 데이터와 Location을 받아오는 등의 작업을 할수있는 face-recognition 라이브러리.
만약 라이브러리에 관심이 있으시면 위에서 소개한 깃허브 페이지에 가서 확인하시고, 여기까지 하겠습니다.
대략 어떤식으로 개발을 하는지는 알았으니, 데이터를 잘 응용하면 유용한 프로그램을 만들수 있겠죠.
- 이상입니다.
인식 성능, 등록된 이미지 검색 방식, 속도, 실제 사람이 아닌 이미지에 대한 보안 처리 등의 개선점은 추후 하나씩 실현하여 개인적으로 정리할 생각으로,
이번엔 안면 인식의 기본적인 형태를 구현하도록 실습했다고 생각하시면 됩니다.
'Computer Vision' 카테고리의 다른 글
| Convolutional Neural Networks 개념 설명 및 실습 (Pytorch CNN 이미지 분류기 구축 + CAM(Class Activation Map)) (0) | 2025.04.19 |
|---|---|
| 딥러닝 기반 포즈 인식(skeleton 탐지) (구 블로그 글 복구) (0) | 2025.04.12 |