- 이번 포스팅에서는 LLM 의 핵심이 되는 모델 구조인 Transformer 를 공부하고 정리하겠습니다.
이론 정리 후 Transformer 의 전체 코드를 작성해서 간단히 학습해보고,
이 모델을 기반으로 어떻게 하여 LLM 이 발전하게 되었는지, 앞으로 LLM 최신 모델을 분석하고 연구하기 위해선 어떻게 해야 하는지에 대해 알아보겠습니다.
- 본 게시글을 이해하시기 위해서는,
딥러닝의 기본 개념과 신경망 학습 원리,
Feed Forward 와 Back Propagation,
Encoding, Normalization, Softmax 등의 기본 내용을 이해하셔야 하며, 코드 설명 해석을 위한 Python 지식이 필요합니다.
인공지능 기본 지식의 경우는 이 게시글에서 소개해드린 프로젝트의 내용을 통해 공부하시거나,
따로 딥러닝 관련 서적으로 공부하신 후 읽으시면 분명 이해가 되실 것입니다.
(Transformer 란?)
- Transformer는 자연어 처리(NLP)를 포함한 다양한 분야에서 핵심적인 역할을 하는 모델 구조로,
2017년 발표한 논문 “Attention is All You Need”에서 처음 제안되었으며, 이후 GPT, BERT, T5 등 많은 강력한 모델들의 기반이 되었습니다.
제가 기억하기로는, 2017 년에 나왔지만 바로 기존 모델들을 대체하지는 못하였고,
제가 본격적으로 딥러닝 독학을 시작하던 2020 년만해도 NLP 영역은 아직 RNN 이 강세여서 RNN 응용 모델 공부만 진행했던 경험이 있습니다.
하지만 이후 Transformer 에 파생하여 BERT 가 나오고, GPT 가 나오며 LLM 에 어텐션 기반의 모델들이 기존 RNN 을 훨씬 추월하는 성능을 보여주며, 현재는 NLP 뿐 아니라 컴퓨터 비전 분야 등에 침투를 한 상태입니다.
조금 늦은 감이 있지만, 저도 이렇게 먼저 Transformer 모델에 대해 공부하고 이해한 후,
실질적으로 최신 연구 내용을 따라갈 정도를 목표로 진행해볼 생각입니다.
(Transformer 가 탄생한 배경)
- 앞서 이야기 했지만, 기존의 자연어와 같이 시간적 순서가 중요한 시계열 데이터를 분석할 때에는 RNN 과, 그에 파생된 LSTM, GRU 가 주류였습니다.
이에 대해 제가 아는 내용을 간략히 정리하자면,
RNN 은 시계열 데이터의 순서에 따른 의미를 추출하기 위하여 아래와 같은 구조를 지닙니다.
[입력 문장] -> [RNN 인코더] -> [Context Vector] -> [RNN 디코더] -> [출력 문장]
간단히 말하자면, 입력값을 고정길이 벡터에 투영하고, 그 벡터를 기반으로 새로운 값을 생성하는 인코더-디코더 구조인데,
RNN 은 그 이름(Recurrent Neural Network : 순환 신경망)과 같이, 인코딩 시에도 순차적으로 입력 및 인코딩을 반복하고, 출력시에도 마찬가지입니다.
예를들어,
'나는', '아이스크림을', '먹었다' 라는 단어를 RNN 에 넣을 때는,
'나는'이라는 데이터와 빈 벡터를 먼저 넣고, 그 인코딩 벡터를 가져온 후,
다음에는 '나는'이라는 인코딩 벡터와 '아이스크림을'이라는 값을 같이 넣어 그 인코딩 벡터를 가져오고,
그 다음에도 동일하게, 이전 상태의 인코딩 벡터와, 이번의 '먹었다'라는 데이터를 넣어서 인코딩 벡터를 만드는 것입니다.
입력값 예시는 아래와 같습니다.
t=1: 입력 = '나는' + 초기 hidden state (보통 0)
→ 결과: hidden₁
t=2: 입력 = '아이스크림을' + hidden₁
→ 결과: hidden₂
t=3: 입력 = '먹었다' + hidden₂
→ 결과: hidden₃
디코더도 마찬가지입니다.
처음에는 인코딩 벡터를 가지고 단어를 생성하고,
다음에는 인코딩 벡터와 이전에 생성된 단어를 넣어서 다음 단어를 생성하는 방식입니다.
이러한 방식으로 딥러닝의 자연어 분석 모델(스팸 탐지기)과 자연어 생성 모델(주로 번역기)에 접근했던 것이죠.
논리를 보았을 때, 값이 투영되는 히든 벡터값만 충분히 크다면 자연어의 희소하고 복잡한 의미를 압축할 수 있는 요소를 갖춘 것으로 보입니다.
하지만, 위 방식의 경우 문제가 있습니다.
의미가 저장되는 히든 벡터 안에 그저 순차적으로 값이 반영되는 것이기에, 무조건 최근에 입력한 값의 성질이 크게 반영됩니다.(정확히는 오래된 데이터의 의미가 갈수록 희석되는 것입니다.)
문장 전체의 의미를 좌우하는 매우 중요한 문장이 꽤나 오래전에 나왔다고 한다면, 그 뒤에 붙는 쓸데없는 단어가 많을수록 진정한 의미를 잃게 되는 것이죠.
이러한 한계로 인해 긴 문장에 대한 RNN 의 성능은 그다지 효과적이지 못했고,
이를 해결하기 위해서 RNN 을 구조적으로 개선한 LSTM 이라는 모델이 나왔습니다.
간단히 설명하자면, Long Short-Term Memory 라는 이름 답게, 오래전에 나온 정보에 대하여, 해당 정보가 중요하다면 지속적으로 환기를 시켜준다는 개념입니다.
LSTM 의 핵심 기능을 쉽게 설명하자면,
중요치 않은 정보는 잊어버리고, 중요하다고 판단되는 데이터의 벡터는 따로 저장해두어 다음 분석에 재활용하며,
만약 그보다 더 중요한 데이터가 나왔다면 이 데이터도 새로 갱신하는 방식으로 오래된 중요한 데이터를 보존하는 기법이죠.
GRU 는 LSTM 을 보다 경량화 하는 개념(그러나 LSTM 보다 특별히 뛰어나다고 할 수도 없었습니다.)일 뿐이지 컨셉은 같습니다.
어쨌건, 위와 같은 노력을 통해 RNN 모델 개선, 학습 방식 변경, 학습 데이터 변경...
이런식으로 NLP 를 진행하면서도 근본적인 문제는 해결하기 어려워 보였습니다.
아무리 LSTM 을 적용한다고 하더라도 문장이 길어질 때 나타나는 의미의 소실은 여전했으며,
RNN 구조의 특징상 입력 -> 인코딩 의 반복이기에, 무조건 이전 작업이 완료되어야 하는 직렬 작업의 한계로 인한 성능 문제는 근본적으로 해결이 불가능 했습니다.
이때 나타난 것이 Attention is All you need, 즉 Attention 과 Transformer 입니다.
- 위에서 RNN 의 문제점을 알아보았고, 그것을 해결하기 위한 노력들을 살펴보았습니다.
이 흐름에서 보았을 때, 실행 성능은 둘째치고서라도 결과물에 대한 퀄리티를 높이기 위해서 근본적으로 해결되어야 할 내용으로는, '문맥 상 중요 데이터의 기억'이라는 것임은 이 글만 읽더라도 확실해 보입니다.
즉, 시간관계를 넘어서 문장 내에서 무엇이 중요하고 무엇이 중요치 않는지를 파악하는 것이 중요하다는 것으로,
앞서 보았던 Attention is all you need. 즉, 어떤 단어에 관심을 기울여야 하는지가 가장 근본적인 시계열 데이터 분석 방식이라는 것이 이번에 설명드릴 Transformer 의 내용입니다.
구현 방법이나 모델의 구조 및 깊은 이론에 대해서는 뒤에서 설명하겠지만,
결국 문장 내에서 무엇이 중요한지 아닌지를 먼저 파악할 수만 있다면, RNN 의 고질적인 문제인 순차적 입력을 할 필요도 없이 한번에 문장 전체를 입력해도 되는 일이므로 순차 입력에 따른 실행 성능의 문제도 해결이 될 것입니다.
- 이렇게 정리하고나니 매우 당연한 해결 방식이 아닐 수 없습니다.
오히려 왜 이전까지는 이런 생각을 하지 못했는지가 궁금해질 정도로요...
하지만 RNN 을 배우는 당시 저는 이러한 해결법을 만들어낼 생각조차 못했었고, 아마 많은 딥러닝 개발자분들 역시 그러했을 것입니다.
그 차이점으로 저는 흐름을 보는 통찰력과, 발상을 현실로 만드는 실력이 필요하다고 생각이 됩니다.
위에서 이렇듯 Transformer 가 생겨난 배경에 대한 흐름을 보았으므로 빠르게 결론에 도출할 수 있던 것이지, 그렇지 않고 단순히 단편적인 기술에만 매달린다면 발상의 전환은 하지 못했을 것이며, 만약 위와 같은 발상이 떠올랐다 하더라도 기본 구현 능력이 없다면 시도할 수 없었을 테니까요.
그런 의미에서 응용은 탄탄한 기본에서 나온다는 것을 다시한번 깨닫습니다.
(Transformer 구조 설명)
- 위에서 이해한 개괄적인 내용을 이제 실제적으로 인공신경망으로 어떻게 구현했는지를 알아보겠습니다.

논문상 공개된 Transformer 모델의 도식은 위와 같습니다.
크게 보자면 앞서 살펴본 RNN 과 같이 입력 인코더와 출력 디코더로 이루어진 모델이라 할 수 있습니다.
- Transformer Encoder
인코더 부분은 아래와 같이 이루어져 있습니다.
입력 임베딩
↓
Positional Encoding (위치 정보 추가)
↓
Multi-Head Self-Attention (문맥 파악)
↓
LayerNorm & Residual
↓
Feed Forward Network (각 위치 독립적 변환)
↓
LayerNorm & Residual
↓
출력
1. 입력 임베딩은 일반적인 NLP 에서 사용하는 텍스트 데이터 전처리와 내용이 같습니다.
정확히는,
입력 -> 토크나이징 -> 임베딩 -> 의미 추출 벡터
이런식으로 자연어 텍스트를 벡터화 하는 것입니다.
RNN 과는 달리, 시계열 데이터를 하나하나 순차적으로 입력하는 것이 아니라, 벡터화된 문장을 한꺼번에 입력하는 것이 특징입니다.
실질적으로 토크나이저는 트랜스포머 안에 포함되지 않지만, 의미를 추출하는 토큰 임베딩의 경우는 모델 안에 포함되어 같이 학습되게 됩니다.
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, emb_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.scale = math.sqrt(emb_size)
def forward(self, tokens):
return self.embedding(tokens.long()) * self.scale
이처럼 Pytorch 로는 기본 제공해주는 임베딩 레이어를 사용하면 간단합니다.
math.sqrt(self.emb_size) 를 곱해주는 이유는, 임베딩 벡터 크기가 커질수록 임베딩 벡터 요소 값의 분산이 커져서 스케일 차이가 커지게 되므로, 이를 스케일링하여 초기 학습시 안정성을 높이기 위한 처리입니다.
2. 위치 인코딩의 경우는,
토큰의 순서를 입력하는 작업입니다.
RNN 같이 순차적으로 입력하지는 않더라도 시간적으로 앞에 위치한 단어인지 뒤에 위치한 단어인지는 중요한 정보입니다.
고로 토큰 임베딩 벡터에 위치값을 포함하는 작업이 필요합니다.
위치 인코딩의 수식은 아래와 같습니다.

pos : 단어의 위치값(0, 1, 2, ..., max_len)
d_model : 단어의 임베딩 벡터 차원 수
i : 임베딩의 차원 인덱스(d_model 까지의 인덱스를 짝수 홀수로 나눠서 사용)
위와 같은 내용일 때, sin 은 짝수 인덱스에, cos 는 홀수 인덱스에 적용하고,
그렇게 나온 PE 를 임베딩 벡터와 더해주어 위치 인코딩이 됩니다.
예를들어,
["나는", "밥을", "먹는다"]
라는 값이 입력되었을 때,
단어 '나는'은 [0.1, 0.2, 0.3, 0.4]
단어 '밥을'은 [0.5, 0.6, 0.7, 0.8]
단어 '먹는다'는 [0.9, 1.0, 1.1, 1.2]
라고 임베딩 벡터로 변환되었다 합시다.
이에 대한 위치 인코딩은 임베딩 벡터와 동일한 사이즈로,
[0, 1, 0, 1]
[0.84, 0.54, 0.01, 1]
[0.91, -0.42, 0.02, 1]
이런 형식으로 만들어지고,
최종적으로 단어 '나는'은, 임베딩 벡터와 위치 인코딩 벡터를 서로 더하여서,
[0.1+0, 0.2+1, 0.3+0, 0.4+1] = [0.1, 1.2, 0.3, 1.4]
이런 식으로 위치 값이 입력되는 것입니다.
수식의 자세한 내용보다는 겉에서부터 이해해나가봅시다.
먼저, 단어 임베딩 벡터와 위치의 의미를 지니는 벡터를 서로 더해도 될까요?
단어 임베딩은 단어의 의미를 표현하기 위해 벡터화된 정보인데, 이에 함부로 값을 더해버린다면 의미가 뒤섞이지 않을까요?
예를들어 김치를 뜻하는 단어 임베딩 벡터가 있을 때, 우연히 이에 어떤 값을 더하니 벌레를 뜻하는 단어 임베딩의 값과 같아진다면 문제가 커질 것입니다.
이는 충분히 가능한 일이지만 걱정할 것은 없습니다.
왜냐면 단어 임베딩 역시 학습을 진행하는 대상이기 때문이죠.
역전파를 통해 학습이 이루어질 때, 단어 임베딩 + 위치 인코딩을 하여 학습되므로, 학습이 진행되는 과정에서 자연스럽게 임베딩 모델이 위치를 고려하는 방향으로 학습되게 될 것입니다.
고로 위치를 의미하는 위치 벡터만 잘 추출한다면 단어 벡터와 위치 벡터의 덧셈은 아무 문제 없이 단어 자체의 의미와 위치의 의미를 포괄하게 될 것이라는 것을 이해할 수 있습니다.(참고로, Transformer 초기 모델은 위치 인코딩을 위 수식으로 행했지만, 이후 BERT, GPT-2 모델은 고정 수식이 아닌 학습 가능한 임베딩 모델로 만들었고, 이후 현 시점 LLM 표준으로 사용되는 RoPE 등의 방법이 나왔습니다.)
그러면 이제 남은 것으로, 왜 Sin Cos 수식으로 위치 벡터를 생성하느냐에 대한 설명을 드리자면,
그냥 Sin Cos 가 만들어내는 조합이 위치별로 고유성을 가지기 때문이라고 생각하시면 됩니다.
Sin Cos 같은 삼각함수는 위아래로 흔들리는 진동을 나타낼 수 있는 대표적인 수식입니다.
위와 같은 수식으로 Sin Cos 를 겹쳐서 위치 벡터를 만든다면,
진동의 파장과 같이 표현될 것이고, 이에따라 위치별로 진동 파장을 다르게 하여 표현한다라고 생각하시면 됩니다.
Sin Cos 의 Position Encoding Vector 에 대한 시각자료를 보여드리자면,
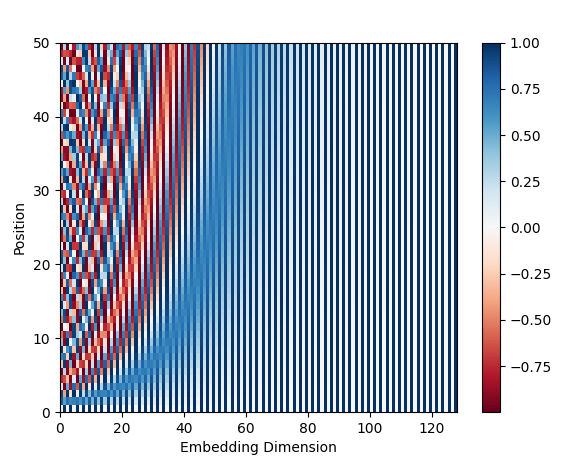
위와 같습니다.
위에서 보이는 그래프상에서 position 은 문장에서의 위치(0번째 단어, 1번째 단어...)를 나타내고,
embedding dimension 은 단어 벡터에서의 차원을 나타냅니다.
색깔의 의미는, 해당 위치에 있는 값이 음수인지 양수인지를 나타내는 것이죠.
즉, position 단위로(가로로) 벡터를 분리해서 본다면, 위치별 값의 패턴이 다르다는 것을 볼 수 있습니다.
이로서 고유값이 보장이 되고, 또한 position 이 커질수록 파형상 진동이 점점 세지는 것을 볼 수 있듯이, 위치가 커짐에 따라 선형적으로 값이 변하게 되므로 가깝고 멀고에 대한 정보도 알 수 있는 것입니다.
이를 코드로 나타낸다면,
class PositionalEmbedding(nn.Module):
def __init__(self, d_model: int, max_len: int = 512):
super().__init__()
position = torch.arange(0, max_len, dtype=torch.float32).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2, dtype=torch.float32) * (-(math.log(10000.0) / d_model))
)
pe = torch.zeros(max_len, d_model, dtype=torch.float32)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pos_embedding', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
seq_len = x.size(1)
return self.pos_embedding[:, :seq_len, :]
Pytorch 로 위와 같이 작성할 수 있습니다.
코드의 중요한 부분은 div_term 부분으로,
sin 이나 cos 안에 위치한 수식에서의 분모 부분을 구현한 것입니다.

이에 position 값을 곱하고, 짝수에는 sin, 홀수에는 cos 를 적용한 부분의 코드가
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
이 부분인 것이죠.
forward 에서 pe 값과 입력값을 서로 더해서 다음으로 넘기는 것이 위치 인코더의 역할의 끝입니다.
3. Multi-Head Attention
앞에까지 해서 단어 의미 + 위치 의미를 지닌 임베딩 벡터를 받아오는 것을 이해하였습니다.
이제 데이터 전처리 부분을 넘어서 본격적인 인코더 부분을 살펴보겠습니다.
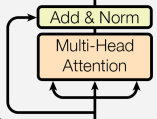
이 부분입니다.
먼저 어텐션이 뭔지에 대해 알아보겠습니다.
간단히 말하자면, 문장 전체의 내용을 해석할 때, 중요한 단어가 뭔지를 판단하는 것입니다.
예를들어 '나는 김치를 너무 좋아해서 매일 먹는다.'라는 문장이 있다고 할 때,
이 문장에서 '먹는다' 라는 단어를 분석할 때, 모델은 '무엇을 먹는지'를 알아야 하므로 핵심이 되는 '김치를'이라는 단어에 집중(Attention) 해야 하죠?
Transformer 의 핵심인 어텐션은,
어떤 단어를 기준으로 다른 단어들을 얼마나 중요하게 여겨야 하는지에 대한 계산이라고 할 수 있습니다.
다시 위 도표를 보자면, 트랜스포머 인코더는 위치 인코딩이 적용된 소스 데이터의 입력 임베딩을 받습니다.
입력 텐서의 차원이 [N, S, D] 라고 하면, 입력 임베딩은 선형 변환을 통해 3개의 임베딩 벡터를 생성합니다.
위에서 입력값이 3갈래로 갈라지는 것을 볼 수 있는데, 이렇게 생성된 벡터를 각각 Query, Key, Value 벡터라고 정의합니다.
각 벡터의 의미는,
Query : 기준이 되는 단어
Key : Query 의 비교 대상이 되는 모든 단어
Value : 단어의 실제 의미
위와 같은 의미입니다.
이런 설명만으론 이해가 어려울 것인데,
예를 들어보겠습니다.
"나는 밥을 먹었다"
라는 문장이 있을 때,
토큰을 "나는", "밥을", "먹었다" 라고 합시다.
각 토큰의 중요성을 가져오기 위해서는 다른 모든 단어들과의 연관성을 찾아야 합니다.
Q = ["나는", "밥을", "먹었다"]
K = ["나는", "밥을", "먹었다"]
V = ["나는", "밥을", "먹었다"]
일 때,
Q 와 K 의 내적(Q*K)을 구하면,
| 나는 | 밥을 | 먹었다 | |
| 나는 | 1 | 2 | 1.5 |
| 밥을 | 2 | 1 | 2 |
| 먹었다 | 1.5 | 2 | 1 |
위와 같이 3x3 행렬이 만들어지며, 이것을 Attention Score 즉, 각 단어가 서로간 얼마나 연관도가 있는지에 대한 값이 됩니다.
위 3x3 행렬과 1x3 의 V 벡터와 서로 행렬곱을 하면, 단어의 의미를 뜻하는 V 값에 어텐션 값이 적용된 값이 1x3 텐서로 나오게 되는 것이죠.
딥러닝의 원리에 따라 위와 같이 역할이 정해졌다면 학습을 진행할 때 마다 적절한 방향으로 수정이 이루어지는 것입니다.
이것이 어텐션의 원리입니다.
코드로 이해하기 위해 먼저 Q, K, V 를 분리하는 방법을 알아보겠습니다.
import torch
import torch.nn as nn
class QKVProjection(nn.Module):
def __init__(self, d_model):
super().__init__()
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
def forward(self, query, key, value):
Q = self.q_proj(query)
K = self.k_proj(key)
V = self.v_proj(value)
return Q, K, V
위와 같이 입력값을 기반으로 선형 함수 레이어를 적용하는 방식으로 만들어집니다.
보시다시피 학습이 가능한 선형 레이어를 통해 변형이 이루어지므로, 딥러닝 학습이 이루어지는 동안 Q, K, V 값이 제 의미를 가지게 될 것입니다.
어텐션의 계산 과정은 아래와 같이 Pseudo 코드로 나타낼 수 있습니다.
scores = Q @ K^T # 유사도: [batch, head, seq_len, seq_len]
scaled = scores / sqrt(d_k) # 안정성 & 학습 속도 향상
weights = softmax(scaled) # 확률 분포 (attention weight)
output = weights @ V # 가중합
Q 에 K 를 행렬곱하면,
Q 에 해당하는 각 단어들에 대해 K 와의 관계가 나올 것입니다.(이 관계값은 Q 와 K 를 선형 변환하는 시점에 학습되어 적용됨)
이렇게 나온 값을 적절한 사이즈로 스케일링하고, 여기에 softmax 를 하여 관계값을 마치 확률처럼 정규화하여 가중치 형태로 변환하는 것입니다.
이제 단어들간의 어텐션이 구해졌으므로, 이것과 V 값을 곱하여 어텐션된 벡터를 구할 수 있는 것입니다.
즉, 학습이 이루어지고 핵심이 되는 부분은 Q, K, V 를 선형 변환 하는 곳이라고 볼 수 있겠네요.
이를 코드로 만들면,
class Attention(nn.Module):
def __init__(self, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))
if mask is not None:
scores = scores.float()
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
p_attn = self.dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
위와 같이 Q * K -> 스케일링 -> softmax -> attention * V 를 구현할 수 있습니다.
다음으로 '멀티 헤드'라는 것을 이해하자면,
위와 같은 어텐션이 N 개 존재한다는 의미입니다.
잘 생각해봅시다.
단어간 관계가 있냐 없냐에 대한 기준은 다양합니다.
관점에 따라 해석을 달리 할 수 있는 것이죠.
이러한 다양한 관점을 표현하기 위하여, 어텐션을 여러개 둠으로써 단일 어텐션보다 더욱 풍부한 관점에서 값을 해석할 수 있는 것으로, 연산량 자체는 N 개를 곱한 만큼 늘겠지만, 병렬 처리가 가능하다는 장점이 있습니다.
코드로 보자면,
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention(dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
x, attn = self.attention(query, key, value, mask=mask)
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
이렇게, query, key, value 를 h 개의 head 로 나누고, 각 head 에 따라 attention 을 수행한 후 head 의 결과를 합쳐 하나의 벡터로 만드는 코드를 작성할 수 있습니다.
이렇게 하여 멀티 헤드로 어텐션화된 벡터를 얻어왔습니다.
다음 단계는, Residual Connection(Add) 과 Layer Normalization(Norm) 입니다.
Residual Connection 은 어텐션 결과와 입력값(즉, 어텐션 입력으로 들어간 임베딩 벡터)을 더하는 것으로,
이렇게 이전 레이어의 값을 한번 더 입력하는 것을 잔차 연결(Residual Connection) 이라고 합니다.
이를 하는 이유는, 주로 오차 역전파 시점에 손실값의 여파를 선명하게 앞쪽으로 전달하여 기울기 소실을 완화시키기 위한 처리입니다.(길이가 매우 길어지는 CNN 계열 모델중 기울기 소실을 해소하기 위해 이를 적용한 ResNet 모델이 있으며, 아마 Transformer 저자도 당시 효과가 좋다는 Residual 기법을 이때 적용해본 것으로 보입니다.)
순전파 시점에서는 어텐션을 적용한 결과물에 다시 한번 단어 의미를 강조하기 위해서도 될 것이고요...
Layer Normalization 은,
앞까지의 단계를 진행하며 얻어진 결과값을 Normalization 하여 출력 벡터의 분포를 안정화하고, 결과적으로 학습을 원활하게 하는 역할을 합니다.
여기까지 하여, Add + Norm 을 코드로 만들면,
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
attn_out, _ = self.mha(x, x, x, mask)
x = self.norm1(x + attn_out) # Add & Norm
return x
이처럼 멀티 헤드 어텐션 이후 Residual + Norm 을 적용한 것을 가시적으로 이해할 수 있습니다.
이 단계에서의 shape 를 살펴보자면,
멀티 헤드를 8개라고 합시다.
입력값이 [4, 512] 형태라고 하고, Q, K, V 로 나누어질 때, 선형변환 되어 [8,4,64] 로 각각 변합니다.
왜 64 라고 하면, 멀티 헤드의 값을 나중에 연결해야하므로, 8 * 64 = 512 이기 때문입니다.
이에 대한 어텐션 스코어 계산 -> 소프트맥스 -> V 에 어텐션 투영 의 과정을 거치면, [8, 4, 64] 가 다시 하나가 됩니다.
Residual 을 할 때에는 차원이 같아야 하므로, [8,4,64] 를 하나로 연결하는 방식으로, [4,512] 로 복구시켜서 Add & Norm 을 진행하여 [4, 512] 입니다.
4. Feed Forward
앞 단계까지 하여 트랜스포머 인코딩까지의 핵심 내용에 대한 이해가 끝난 것입니다.
이제 남은것은, 단어 의미 + 위치 정보 + 어텐션 정보 까지 입력된 진정한 의미에서의 문장 의미 벡터를 해석하는 일 뿐입니다.
이 과정은 매우 간단한 것으로, 일반적인 딥러닝 회귀 모델과 동일한 Feed Forward 레이어를 추가하기만 하면 되는 일입니다.
빠르게 코드로만 알아봅시다.
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
attn_out, _ = self.mha(x, x, x, mask)
x = self.norm1(x + attn_out) # Add & Norm
ffn_out = self.ffn(x)
x = self.norm2(x + ffn_out) # Add & Norm
return x
앞서 Add & Norm 에 합쳐서,
Feed Forward(FF) 레이어와, 추가적인 Add & Norm 을 추가하였습니다.
인코더의 마지막 부분으로,
위를 보시면 일반적인 딥러닝의 FF 레이어와 같이, 선형 레이어 -> 활성 함수 -> 출력 함수 의 정석적인 형태를 지닙니다.
단어의 의미를 축약하는 부분으로 사용되며, 어텐션이 적용된 벡터를 '어떻게 해석하는지'에 대하여 학습되어 사용되는 부분입니다.
이렇게 얻어낸 출력 벡터에 또 Redidual 을 적용하고 정규화를 하는 것을 마지막으로 트랜스포머 인코더가 마무리됩니다.
(여기서 결과 벡터는 앞서 받아온 [4,512] 로 줘도 되고, FF 레이어로 축약 혹은 확장을 해도 됩니다.)
참고로 인코더는 N개가 존재합니다.
이유는, 멀티 헤드 어텐션에서 평행적인 관점별 해석을 위해 N개의 어텐션을 둔 것처럼,
보다 깊이있는 해석을 위한 것인데, 멀티 헤드 어텐션과 다른점으로는 병렬이 아니라 직렬 연결이라는 것입니다.
인코더 1이 해석한 벡터를 인코더 2가 받아들이고, 다시 인코더 3이 받아들이는 방식으로,
이렇게 인코더를 많이 쌓을수록 해석 능력이 좋아지며, 이렇게 많은 계층(인코더 혹은 디코더)을 쌓는 것을 LLM 이라고 합니다.
(인코더를 많이 쌓을수록 단어간 관계 파악에서 시작하여 문장 구문 이해, 문장 추상 의미 이해 등의 더욱 깊은 표현을 학습 할 수 있게 됩니다. 하지만 당연히 학습시킬 파라미터가 증가할수록 그것을 학습시키기 위한 어마어마한 데이터가 필요합니다.)
또한 트랜스포머 인코더의 의의는,
시계열 데이터에 어텐션이란 개념을 적용해서 해석한다는 것입니다.
이러한 특성으로 인하여 전후관계 및 상관관계가 중요한 데이터를 인코딩 할 때 주요하게 사용되며,
이를 응용한 대표적인 모델은 BERT, ViT, T5 등이 존재합니다.
5. 인코더 부분을 마치기 전에 인코더 코드를 확인해봅시다.
class EncoderLayer(nn.Module):
def __init__(self, emb_size, nhead, dim_feedforward, dropout=0.1):
super().__init__()
self.self_attn = MultiheadAttention(emb_size, nhead, dropout=dropout)
self.linear1 = nn.Linear(emb_size, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, emb_size)
self.norm1 = nn.LayerNorm(emb_size)
self.norm2 = nn.LayerNorm(emb_size)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = F.relu
def forward(self, src, src_mask=None, src_key_padding_mask=None):
# src: (seq_len, batch_size, emb_size)
src2, _ = self.self_attn(
src, src, src,
attn_mask=src_mask,
key_padding_mask=src_key_padding_mask
)
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src # (seq_len, batch_size, emb_size)
위 인코더 레이어가 인코더 유닛 하나를 의미합니다.
src 값을 그대로 3개로 하여 셀프 어텐션 레이어에 입력하여 어텐션이 적용된 src2 벡터를 가져오고,
이 값을 src 와 더하여 regidual 을 만든 후 norm 을 적용하는 것으로 끝입니다.
class Encoder(nn.Module):
def __init__(self, num_layers, emb_size, nhead, dim_feedforward, dropout):
super().__init__()
self.layers = nn.ModuleList([
EncoderLayer(emb_size, nhead, dim_feedforward, dropout)
for _ in range(num_layers)
])
def forward(self, src, mask=None, src_key_padding_mask=None):
# src: (seq_len, batch_size, emb_size)
output = src
for layer in self.layers:
output = layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
return output # (seq_len, batch_size, emb_size)
인코더 전체 부분은 위에서 설명했듯 인코더 유닛 레이어를 얼마든 겹쳐서 만들 수 있으며,
위에서 보시는 것 처럼 num_layers 크기만큼 인코더 레이어가 쌓이는 형태입니다.
- Transformer Decoder
다음으로 디코더 부분은 아래와 같이 이루어져 있습니다.
입력(시작 토큰 또는 이전 단어들)
↓
Positional Encoding
↓
Masked Multi-Head Self-Attention (미래 단어는 못 보게 차단)
↓
LayerNorm & Residual
↓
Encoder-Decoder Attention (인코더 출력 벡터와 상호작용)
↓
LayerNorm & Residual
↓
Feed Forward Network
↓
LayerNorm & Residual
↓
출력 벡터 → Softmax → 단어 예측
앞서 인코더 부분을 진행했다면 이미 이해한 내용들이 많을 것입니다.
구조적으로 왜 저러한 형태를 지녔는지를 확인해보죠.
디코더의 동작 방식은 아래와 같습니다.
예를 들어, "I am"이라는 텍스트가 주어졌을 때,
1단계: "I"만을 보고 "am"을 예측
2단계: "I am"을 보고 "a"를 예측
3단계: "I am a"를 보고 "student"를 예측
이처럼 이전 토큰을 기반으로 다음 토큰을 점진적으로 생성합니다.
외부적인 구조를 보았을 때, Transformer 모델의 입력값은 2개입니다.
영문 -> 불어 번역기로 예를 들겠습니다.
"I am a student" 를, "Je suis etudiant" 라고 번역한다고 합시다.
그러면 뭐가 필요할까요?
번역할 대상인 "I am a student" 의 의미를 축약한 벡터, 즉 인코더로 해석한 문장 의미 벡터가 필요합니다.
그리고 디코더 자체적인 입력값은 토큰을 하나하나 생성하며 이전 출력 토큰들을 넣어주는 역할을 합니다.
예를들어, 문장 시작시에는 아직 출력된 값이 없으므로 "<start>" 라는 토큰이 입력됩니다.(예약 토큰으로, 문장이 시작된다는 것을 의미입니다. 당연히 학습시 예약 토큰과 동일한 단어는 못 들어가도록 처리해야합니다.)
그리고 이를 통해 "je" 가 생성되면, 다음 스탭에서는 "je" 를 입력하여 인코딩 벡터와 결합하여 "je suis" 를 만들어냅니다.
다음 스탭으로는 "je suis" 를 가지고 그 다음에 올 단어를 찾는 것이죠? 그러면 "je suis" 를 입력하여 "je suis etuant" 를 만들어냅니다.
만약 "je suis etuant" 까지 만들어서 더이상 만들 문장이 없다고 판단하면, "<eos>" 를 반환하여 문장 생성을 끊습니다.
인코더와 연관한 전체 동작을 복습 및 정리하면,
1. 인코더에 번역하고 싶은 문장을 통째로 넣어서 한꺼번에 의미를 추출하는 인코딩을 실행하여 인코딩 벡터를 출력한다
2. 디코더는 인코더의 벡터와 직전까지 생성했던 디코딩 결과물을 같이 받아 결과를 출력한다.
3. 디코더는 <eos> 와 같은 문장 끝이 나올 때 까지 2번을 반복한다.
트랜스포머는 이러한 동작을 수행함을 알 수 있습니다.
이제 전체 동작을 이해했으니 하나씩 확인하겠습니다.
1. 입력 임베딩 + 위치 인코딩
생성된 데이터를 임베딩 및 위치 인코딩을 하는 것입니다.
처음에는 <start>, 다음에는 <start> je, 그 다음에는 <start> je suis, ... 이런식으로 인코딩하여 넘겨줍니다.
코드는 트랜스포머 인코더 부분의 코드와 동일합니다.
2. Masked Multi-Head Self-Attention
트랜스포머 디코더의 핵심 부분입니다.
기본적으로는 멀티 헤드 어텐션과 동일한데, 앞서 전체 동작에서 살펴보았듯 이전까지 생성된 문장을 넣어서 멀티 헤드 어텐션을 진행하면 됩니다.
논문상 중요한 차이점으로는 Masking 이 있습니다.
앞서 작성했던 MHA 를 그대로 사용하면 되는데,
인코더에서는 mask 파라미터를 안 넣어도 되고, 디코더에서는 mask 를 넣어줘야만 하죠.
이유는, 모든 정보를 처음부터 입력받는 인코더 모델과 달리,
토큰 단위로 문장을 생성해나가야 하는 디코더 모델은 미래의 토큰은 모르는 상태여야 합니다.
번역기 모델을 예를들면,
학습 시점에는 "i am a boy" -> "나는 소년입니다." 라는 학습 자료가 존재하고 있을 때, 디코더를 학습시키는 시점에 위 정보를 그대로 넣을 수도 있겠지만, 그러면 모델은 모든 정보가 주어진 상태에서만 추론을 할 수 있게 학습될 것입니다.
"i am a boy" 가 인코딩되었을 때,
처음에는 "나는" 을,
"나는" 이 출력된 시점에는 "소년" 을,
"나는 소년" 이 출력된 시점에는 "입니다" 를,
"나는 소년 입니다" 가 출력된 시점에는 출력을 멈출 수 있도록 학습하려면,
학습 자료에서 현재 추론하려는 단어의 위치보다 미래의 토큰 입력값은 가려야만 하며,
그 결과,
[
[0, -inf, -inf, -inf],
[0, 0, -inf, -inf],
[0, 0, 0, -inf],
[0, 0, 0, 0]
]
이런 형식의 마스크를 '더하여', 가려야 하는 부분의 값이 -inf 가 되도록 해야 하는 것입니다.
if attn_mask is not None:
scores += attn_mask.unsqueeze(0).unsqueeze(0)
이 코드가 실행되어 attn_mask 값과 스코어 값이 합쳐져서,
attn_mask 안에 -inf 인 값과 합친다면 합친 값이 -inf 가 되므로 이 값이 softmax 로 입력되면 값이 0 이 되어 해당 부분의 V 값을 지우는 기능을 하게 되죠.
3. 인코딩 벡터를 받는 멀티 헤드 어텐션 + 포워딩
앞서 문장 전체의 의미를 가지는 인코딩 벡터와, 현재까지 출력된 데이터의 의미를 지니는 벡터가 준비되었습니다.
이제 다음의 새로운 정보를 출력할 준비물이 갖추어졌으며, 남은 것은 이 둘을 융합하는 것 뿐입니다.
디코더의 두번째 멀티 헤드 어텐션이 두 벡터를 융합하는 역할을 합니다.
동일하게 Q, K, V 로 어텐션을 계산하는데,
K, V 는 인코딩 벡터를 사용하고, Q 는 디코더 출력 벡터를 사용합니다.
그 이유를 해석해보자면,
Q 가 비교 기준이 되는 단어를 의미하며,
K 는 비교 대상이 되는 다른 모든 단어를 의미합니다.
현 시점의 단어에 대하여 의미를 가지는 인코딩 벡터의 모든 단어와의 연관관계를 계산하고, 여기서 나온 '다음 생성에 중요한 단어' 정보를 인코딩 벡터인 V 에 반영한다면,
결국 문장 전체의 의미 중 이번 스탭에서 주의를 기울여야 하는 단어들이 표시되는 것입니다.
이제 이 값을 가지고 순전파를 거쳐서 정보를 정리한 후,
다음 추론할 단어의 의미를 지닌 이 벡터를 가지고 다음 단어를 예측해낸다는 것으로 디코더의 역할을 완전히 이해할 수 있었습니다.
인코더와 마찬가지로 디코더 역시 N개의 디코더를 직렬로 쌓을 수 있습니다.
멀티 헤드 어텐션에서 순방향 신경망 까지의 디코더를 N 개 쌓으면, 역시나 더 추상적이고 깊은 내용을 이해할 수 있게 됩니다.
트랜스포머 디코더에서 파생된 모델은,
그 유명한 GPT 모델이 있으며, LLaMA 역시 그러합니다.
디코더 파생 생성형 AI 가 트랜스포머 디코더와 다른점은,
인코더 부분이 아예 존재하지 않는다는 것이고,
그렇기에 인코딩 벡터를 받아들이는 두번째 멀티 헤드 어텐션이 없다는 것입니다.
결국 마스크 멀티 헤드 어텐션 + 순방향 신경망의 조합으로 데이터를 생성하는 모델이라고 볼 수 있습니다.
4. 트랜스포머 디코더 역시 마지막으로 디코더 레이어와 디코더 코드를 보겠습니다.
class DecoderLayer(nn.Module):
def __init__(self, emb_size, nhead, dim_feedforward, dropout=0.1):
super().__init__()
self.self_attn = MultiheadAttention(emb_size, nhead, dropout=dropout)
self.multihead_attn = MultiheadAttention(emb_size, nhead, dropout=dropout)
self.linear1 = nn.Linear(emb_size, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, emb_size)
self.norm1 = nn.LayerNorm(emb_size)
self.norm2 = nn.LayerNorm(emb_size)
self.norm3 = nn.LayerNorm(emb_size)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = F.relu
def forward(
self,
tgt,
memory,
tgt_mask=None,
memory_mask=None,
tgt_key_padding_mask=None,
memory_key_padding_mask=None,
):
# tgt: (seq_len, batch_size, emb_size)
# memory: (src_seq_len, batch_size, emb_size)
tgt2, _ = self.self_attn(
tgt, tgt, tgt,
attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask
)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2, _ = self.multihead_attn(
tgt, memory, memory,
attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask
)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt # (seq_len, batch_size, emb_size)
디코더 레이어 코드는 입력 부분에서는 디코더에 입력된 tgt 를 멀티 헤드 어텐션으로 적용하고,
인코더 벡터를 받아오는 부분에서는 앞서 설명한대로 K, V 는 인코더 벡터(메모리), Q 는 디코더 어텐션이 작용한 tgt 벡터를 입력하는 것으로 앞서 설명과 같으며,
class Decoder(nn.Module):
def __init__(self, num_layers, emb_size, nhead, dim_feedforward, dropout):
super().__init__()
self.layers = nn.ModuleList([
DecoderLayer(emb_size, nhead, dim_feedforward, dropout)
for _ in range(num_layers)
])
def forward(
self,
tgt,
memory,
tgt_mask=None,
memory_mask=None,
tgt_key_padding_mask=None,
memory_key_padding_mask=None
):
# tgt: (tgt_seq_len, batch_size, emb_size)
# memory: (src_seq_len, batch_size, emb_size)
output = tgt
for layer in self.layers:
output = layer(
output,
memory,
tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask
)
return output # (tgt_seq_len, batch_size, emb_size)
디코더 역시 디코더 레이어를 쌓아서 만든 구조를 그대로 만든 것입니다.
- 이론 정리 마지막으로 트랜스포머 학습 방식에 대해 이해하겠습니다.
트랜스포머 모델은 기본적으로 Seq2Seq 구조입니다.
즉, 문장을 넣으면 문장을 반환하는 모델입니다.
학습 데이터는 인코더에 의해 분석될 대상인 입력 문장들과 모델이 반환하길 기대하는 정답 문장들의 쌍이 필요합니다.
예를들어 번역 모델을 학습시키려면, 번역 대상 문장과 번역 완료 문장을 넣어주고,
질의응답 모델은 질문 문장과 답변 문장을 넣어주는 것입니다.
트랜스포머 모델의 학습 과정은,
1. 입력 시퀀스 토크나이징
2. 토큰 → 임베딩 + 위치 인코딩
3. 인코더/디코더 통과 → 출력 로짓(logits)
4. 소프트맥스(softmax)로 확률 분포 계산
5. 정답 토큰과 비교하여 손실 계산
6. 역전파(Backpropagation) 수행
7. 파라미터 업데이트 (optimizer 사용)
8. 다음 배치로 반복
위와 같으며,
손실 함수는 softmax 출력층의 값을 통한 단어 분류 문제이니만큼,
분류 문제에 많이 사용되는 Cross Entropy 를 사용합니다.
직접 보며 이해하는 것이 좋을 것이기에 아래 코드를 작성하며 확인하겠습니다.
- 트랜스포머 모델 Pythorch 코드
transformer.py
import math
import torch
from torch import nn
import torch.nn.functional as F
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, emb_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.scale = math.sqrt(emb_size)
def forward(self, tokens):
return self.embedding(tokens.long()) * self.scale
class PositionalEmbedding(nn.Module):
def __init__(self, d_model: int, max_len: int = 512):
super().__init__()
position = torch.arange(0, max_len, dtype=torch.float32).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2, dtype=torch.float32) * (-(math.log(10000.0) / d_model))
)
pe = torch.zeros(max_len, d_model, dtype=torch.float32)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pos_embedding', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
seq_len = x.size(1)
return self.pos_embedding[:, :seq_len, :]
class InputEmbedding(nn.Module):
def __init__(self, vocab_size, d_model, dropout=0.1, max_len: int = 512):
super().__init__()
self.token = TokenEmbedding(vocab_size, d_model)
self.position = PositionalEmbedding(d_model, max_len)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
token_emb = self.token(x)
pos_emb = self.position(x)
return self.dropout(token_emb + pos_emb)
class Attention(nn.Module):
def __init__(self, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))
if mask is not None:
scores = scores.float()
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
p_attn = self.dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention(dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
x, attn = self.attention(query, key, value, mask=mask)
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super().__init__()
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True, unbiased=False)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super().__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
class ReLU(nn.Module):
def forward(self, x):
return torch.clamp(x, min=0)
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.activation = ReLU()
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.linear1(x)
x = self.activation(x)
x = self.linear2(x)
return self.dropout(x)
class EncoderBlock(nn.Module):
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
super().__init__()
self.attention = MultiHeadedAttention(attn_heads, hidden, dropout)
self.feed_forward = PositionwiseFeedForward(hidden, feed_forward_hidden, dropout)
self.input_sublayer = SublayerConnection(hidden, dropout)
self.output_sublayer = SublayerConnection(hidden, dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return x
class Encoder(nn.Module):
def __init__(self, d_model=512, n_enc_layers=6, heads=8, d_ff=2048, dropout=0.1):
super().__init__()
self.encoder_layers = nn.ModuleList([
EncoderBlock(d_model, heads, d_ff, dropout) for _ in range(n_enc_layers)
])
def forward(self, src_emb, src_mask=None):
x = src_emb
for layer in self.encoder_layers:
x = layer(x, src_mask)
return x
class DecoderBlock(nn.Module):
def __init__(self, d_model, heads, d_ff, dropout):
super().__init__()
self.self_attention = MultiHeadedAttention(heads, d_model, dropout)
self.cross_attention = MultiHeadedAttention(heads, d_model, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.sublayers = nn.ModuleList([
SublayerConnection(d_model, dropout),
SublayerConnection(d_model, dropout),
SublayerConnection(d_model, dropout)
])
def forward(self, x, self_mask, enc_output, enc_mask):
x = self.sublayers[0](x, lambda _x: self.self_attention(_x, _x, _x, mask=self_mask))
x = self.sublayers[1](x, lambda _x: self.cross_attention(_x, enc_output, enc_output, mask=enc_mask))
x = self.sublayers[2](x, self.feed_forward)
return x
class Decoder(nn.Module):
def __init__(self, d_model=512, n_dec_layers=6, heads=8, d_ff=2048, dropout=0.1):
super().__init__()
self.decoder_layers = nn.ModuleList([
DecoderBlock(d_model, heads, d_ff, dropout) for _ in range(n_dec_layers)
])
def forward(self, dec_emb, tgt_mask, enc_output, src_mask):
x = dec_emb
for layer in self.decoder_layers:
x = layer(x, tgt_mask, enc_output, src_mask)
return x
class Transformer(nn.Module):
def __init__(
self,
num_encoder_layers,
num_decoder_layers,
vocab_size_src,
vocab_size_tgt,
emb_size,
nhead,
dim_feedforward,
dropout,
max_len,
pad_token_id
):
super().__init__()
self.src_emb = InputEmbedding(vocab_size_src, emb_size, dropout, max_len)
self.tgt_emb = InputEmbedding(vocab_size_tgt, emb_size, dropout, max_len)
self.encoder = Encoder(emb_size, num_encoder_layers, nhead, dim_feedforward, dropout)
self.decoder = Decoder(emb_size, num_decoder_layers, nhead, dim_feedforward, dropout)
self.generator = nn.Linear(emb_size, vocab_size_tgt, bias=False)
self.pad_token_id = pad_token_id
def _make_src_mask(self, src):
return (src != self.pad_token_id).unsqueeze(1).unsqueeze(2)
def _make_tgt_mask(self, tgt):
batch, tgt_len = tgt.size()
subsequent_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=tgt.device, dtype=torch.bool)).unsqueeze(
0).unsqueeze(1)
pad_mask = (tgt != self.pad_token_id).unsqueeze(1).unsqueeze(2)
return pad_mask & subsequent_mask
def forward(self, src, tgt):
src_mask = self._make_src_mask(src)
tgt_mask = self._make_tgt_mask(tgt)
src_emb = self.src_emb(src)
tgt_emb = self.tgt_emb(tgt)
memory = self.encoder(src_emb, src_mask)
output = self.decoder(tgt_emb, tgt_mask, memory, src_mask)
return self.generator(output)
def encode(self, src, src_mask=None):
src_emb = self.src_emb(src)
return self.encoder(src_emb, src_mask)
def decode(self, tgt, memory, tgt_mask=None, src_mask=None):
tgt_emb = self.tgt_emb(tgt)
return self.decoder(tgt_emb, tgt_mask, memory, src_mask)
트랜스포머 모델 코드는 통합하여 위와 같습니다.
이미 위에서 설명한 내용은 생략하며,
각 부분을 조합한 Transformer 가 위와 같이 존재합니다.
train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from datasets import load_dataset
from transformers import AutoTokenizer
from tqdm import tqdm
from transformer import Transformer
# 하이퍼파라미터 설정
BATCH_SIZE = 64
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 2048
NUM_ENCODER_LAYERS = 6
NUM_DECODER_LAYERS = 6
DROPOUT = 0.1
MAX_LEN = 128
EPOCHS = 10
PAD_TOKEN = "<pad>"
# 데이터셋 로드 및 전처리
dataset = load_dataset("wmt14", "de-en", split={"train": "train[:1%]", "valid": "validation[:1%]"})
# tokenizer는 HuggingFace의 pre-trained tokenizer 사용 (예: t5-small)
tokenizer_src = AutoTokenizer.from_pretrained("bert-base-german-cased")
tokenizer_tgt = AutoTokenizer.from_pretrained("bert-base-uncased")
# <pad> 토큰 id
pad_token_id = tokenizer_tgt.pad_token_id
# 토크나이즈 함수
def tokenize_fn(example):
src_text = example["translation"]["de"]
tgt_text = example["translation"]["en"]
src = tokenizer_src(src_text, truncation=True, padding="max_length", max_length=MAX_LEN, return_tensors="pt")
tgt = tokenizer_tgt(tgt_text, truncation=True, padding="max_length", max_length=MAX_LEN, return_tensors="pt")
return {
"src_input": src.input_ids.squeeze(0),
"tgt_input": tgt.input_ids.squeeze(0)[:-1],
"tgt_output": tgt.input_ids.squeeze(0)[1:]
}
# 전처리 적용
dataset["train"] = dataset["train"].map(tokenize_fn)
dataset["valid"] = dataset["valid"].map(tokenize_fn)
# PyTorch Dataset으로 변환
class TranslationDataset(torch.utils.data.Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
return (
torch.tensor(item["src_input"], dtype=torch.long),
torch.tensor(item["tgt_input"], dtype=torch.long),
torch.tensor(item["tgt_output"], dtype=torch.long),
)
train_loader = DataLoader(TranslationDataset(dataset["train"]), batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(TranslationDataset(dataset["valid"]), batch_size=BATCH_SIZE)
# 모델 초기화
model = Transformer(
num_encoder_layers=NUM_ENCODER_LAYERS,
num_decoder_layers=NUM_DECODER_LAYERS,
vocab_size_src=tokenizer_src.vocab_size,
vocab_size_tgt=tokenizer_tgt.vocab_size,
emb_size=EMB_SIZE,
nhead=NHEAD,
dim_feedforward=FFN_HID_DIM,
dropout=DROPOUT,
max_len=MAX_LEN,
pad_token_id=pad_token_id
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 옵티마이저 및 손실 함수
optimizer = optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss(ignore_index=pad_token_id)
# 학습 루프
for epoch in range(EPOCHS):
model.train()
total_loss = 0
for src, tgt_in, tgt_out in tqdm(train_loader, desc=f"Epoch {epoch + 1}"):
src, tgt_in, tgt_out = src.to(device), tgt_in.to(device), tgt_out.to(device)
optimizer.zero_grad()
output = model(src, tgt_in)
loss = criterion(output.view(-1, output.size(-1)), tgt_out.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch + 1} Training Loss: {total_loss / len(train_loader):.4f}")
# 검증 루프
model.eval()
val_loss = 0
with torch.no_grad():
for src, tgt_in, tgt_out in valid_loader:
src, tgt_in, tgt_out = src.to(device), tgt_in.to(device), tgt_out.to(device)
output = model(src, tgt_in)
loss = criterion(output.view(-1, output.size(-1)), tgt_out.view(-1))
val_loss += loss.item()
print(f"Epoch {epoch + 1} Validation Loss: {val_loss / len(valid_loader):.4f}")
torch.save(model, "model_full.pth")
학습 데이터는 독일어 - 영어 번역을 위한 wmt14 데이터셋을 사용하였습니다.
Transformer 모델에 번역 대상 문장과 번역 정답 문장을 같이 넣어서 모델이 생성한 문장을 가져오게 합니다.
학습 과정을 알기 쉽게 예시로 설명하겠습니다.
Seq2SeqTransformer 의 forward 의 디코더 입력값이 [<bos>, Ich, bin, ein, Junge] 이렇게 입력되면 그 결과값은 [Ich, bin, ein, Junge, <eos>] 이런 형식으로(잘 학습 되었을 시 위와 같이 출력됩니다.) 나온다고 생각하면 됩니다.
이해를 돕기 위해 추가로 설명하면,
[<bos>, Ich, bin, ein] 를 입력시에는[Ich, bin, ein, Junge] 이렇게, 입력한 값의 다음 토큰까지를 예측해 반환하는 것입니다.
디코더의 멀티 헤드 어텐션이 입력된 [<bos>, Ich, bin, ein, Junge] 에 대하여 어텐션 스코어가 반영된 V 벡터를 반환하는 것이고,(이때 어텐션 값에 미래 데이터가 영향을 주지 않게 미래 데이터에 대한 마스킹 적용)
이 V 벡터에 따라 이전에 입력된 데이터를 포함해서 바로 다음의 토큰까지를 예측하는 것이 트랜스포머 forward 의 동작입니다.
만약 학습이 잘 안된 상태라면,
정답이 [Ich, bin, ein, Junge, <eos>] 이렇게 나와야 하지만,
[fsdf, sfe, vdsf, sdfe, fffe] 이렇게 전부 올바르지 않은 답이 나올 수 도 있습니다.
이러한 성질을 이용해서, 위 학습 코드에서는 모델에 값을 입력하고, 그 모델에서 반환된 위와 같은 값을 정답값과 비교하여 그 loss 값을 구하며, 이를 기반으로 학습을 시켜 한 문장 단위로 올바른 단어들을 예측 하게 하는 것입니다.
결과는 아래와 같으며,
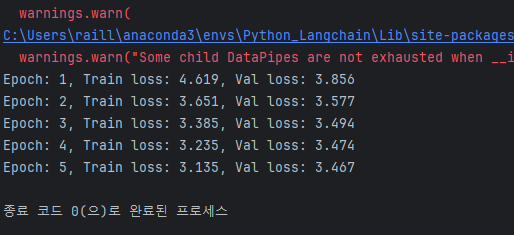
학습시 시간이 엄청 걸립니다.
test.py
import torch
from transformers import AutoTokenizer
from transformer import Transformer
# 하이퍼파라미터 - 학습 시와 동일하게 유지
MAX_LEN = 128
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 모델 및 토크나이저 로드
tokenizer_src = AutoTokenizer.from_pretrained("bert-base-german-cased")
tokenizer_tgt = AutoTokenizer.from_pretrained("bert-base-uncased")
pad_token_id = tokenizer_tgt.pad_token_id
# 모델 로드
model = torch.load("model_full.pth", map_location=DEVICE, weights_only=False)
model.eval()
# 번역 함수
def translate_sentence(sentence_de):
# 1. 독일어 문장을 토크나이즈
tokens_src = tokenizer_src(sentence_de, return_tensors="pt", padding="max_length", truncation=True, max_length=MAX_LEN)
src_input = tokens_src["input_ids"].to(DEVICE)
# 2. 인코더에 입력
src_mask = model._make_src_mask(src_input)
memory = model.encode(src_input, src_mask)
# 3. 디코더 초기 입력 (<pad> or <bos> 토큰으로 시작)
tgt_tokens = torch.full((1, 1), tokenizer_tgt.cls_token_id or tokenizer_tgt.pad_token_id, dtype=torch.long, device=DEVICE)
# 4. 토큰을 하나씩 생성
for _ in range(MAX_LEN):
tgt_mask = model._make_tgt_mask(tgt_tokens)
out = model.decode(tgt_tokens, memory, tgt_mask=tgt_mask, src_mask=src_mask)
logits = model.generator(out[:, -1]) # 마지막 위치
next_token = logits.argmax(dim=-1).unsqueeze(1) # Greedy decoding
tgt_tokens = torch.cat([tgt_tokens, next_token], dim=1)
# 종료 조건: [SEP] 또는 [PAD] 토큰이면 중단
if next_token.item() in [tokenizer_tgt.sep_token_id, tokenizer_tgt.pad_token_id]:
break
# 5. 디코더 출력에서 첫 토큰 제거하고 복호화
output_tokens = tgt_tokens.squeeze(0).tolist()[1:] # 첫 토큰 제거
translated_text = tokenizer_tgt.decode(output_tokens, skip_special_tokens=True)
return translated_text
# 예시 문장
german_sentence = "Guten Morgen, wie geht es dir?"
translated = translate_sentence(german_sentence)
print(f"German: {german_sentence}")
print(f"English: {translated}")
마지막으로 테스트 코드는 위와 같습니다.
테스트 코드까지 이해했다면 이해하기 쉽습니다.
먼저 재활용할 모델의 인코딩 결과를 memory 로 저장하고,
이를 번역할 때에는, decode 를 사용하여 값 생성을 반복합니다.
<bos> 에서 시작해서,
<bos> a ->
<bos> a group ->
<bos> a group of -> ...
이런식으로, <eos> 가 반환될 때까지 for 문을 돌려서 decode & generator 를 돌리는 것입니다.(greedy_decode)
이렇게 얻은 문장 토큰들을 해석해서 string 으로 돌리는 것이 translate 의 방식입니다.

학습 5 에포크 만에 위와 같이 독일어 -> 영어 번역이 가능해졌습니다.
개인용 컴퓨터 하나(GPU 포함)로도 약 30분 정도의 시간으로 학습이 가능하며, 성능도 보시는바와 같이 나쁘지 않다고 판단됩니다.
- 이상입니다.
다음 게시글은 Transformer 에서 파생된 GPT, BERT 모델에 대해 알아볼 것이고,
이후 LLM 개발 경쟁에서 나타난 GPT 개선 모델이나 LLaMA, DeepSeek 와 같은 굵직한 모델들을 알아볼 것이며,
ViT, MultiModal 등의 응용 모델 부분을 익히면 될 것 같습니다.
'Study > NLP' 카테고리의 다른 글
| [딥러닝] BERT 모델 정리(Encoder Only Transformer, Pytorch BERT 자연어 인코딩 모델 구현) (0) | 2025.05.27 |
|---|---|
| [딥러닝] GPT 모델 정리(Decoder Only Transformer, Pytorch GPT-1 자연어 생성 모델 구현) (0) | 2025.05.25 |
| [LLM] LLM 모델 Multi-Modal 에 대한 기본 이해와 적용(이미지 + 텍스트 해석 AI 구현) (1) | 2025.05.21 |
| [Langchain] 생성형 AI 서버 구축 (LLM 모델 네트워크 서빙 방식 정리) (0) | 2025.05.21 |
| [Langchain] VectorDB 를 이용한 LLM 검색 증강(RAG) 고도화 (0) | 2025.05.20 |